2022-06-01 16:42:08 -06:00
# Diffusers
2022-06-02 04:27:01 -06:00
## Definitions
2022-06-02 04:15:59 -06:00
2022-06-02 04:27:01 -06:00
**Models**: Single neural network that models p_θ(x_t-1|x_t) and is trained to “denoise” to image
*Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet*
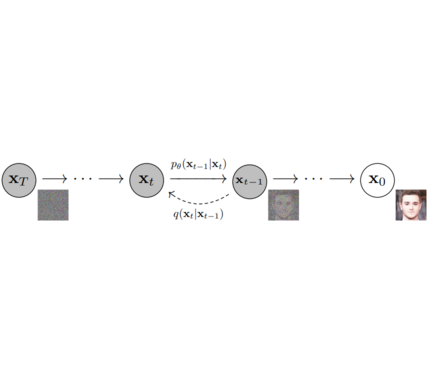
**Samplers**: Algorithm to *train* and *sample* from **Model** . Defines alpha and beta schedule, timesteps, etc..
*Example: Vanilla DDPM, DDIM, PMLS, DEIN*


**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, CLIP
*Example: GLIDE,CompVis/Latent-Diffusion, Imagen, DALL-E*
2022-06-02 04:15:59 -06:00
2022-06-02 07:59:58 -06:00
## 1. `diffusers` as a central modular diffusion and sampler library
`diffusers` should be more modularized than `transformers` so that parts of it can be easily used in other libraries.
2022-06-06 11:36:24 -06:00
It could become a central place for all kinds of models, schedulers, training utils and processors required when using diffusion models in audio, vision, ...
2022-06-02 07:59:58 -06:00
One should be able to save both models and samplers as well as load them from the Hub.
Example:
```python
import torch
2022-06-06 09:43:36 -06:00
from diffusers import UNetModel, GaussianDDPMScheduler
import PIL
import numpy as np
generator = torch.Generator()
generator = generator.manual_seed(6694729458485568)
2022-06-07 07:13:39 -06:00
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
2022-06-06 09:43:36 -06:00
# 1. Load models
scheduler = GaussianDDPMScheduler.from_config("fusing/ddpm-lsun-church")
model = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
# 2. Sample gaussian noise
image = scheduler.sample_noise((1, model.in_channels, model.resolution, model.resolution), device=torch_device, generator=generator)
# 3. Denoise
for t in reversed(range(len(scheduler))):
# i) define coefficients for time step t
clip_image_coeff = 1 / torch.sqrt(scheduler.get_alpha_prod(t))
clip_noise_coeff = torch.sqrt(1 / scheduler.get_alpha_prod(t) - 1)
image_coeff = (1 - scheduler.get_alpha_prod(t - 1)) * torch.sqrt(scheduler.get_alpha(t)) / (1 - scheduler.get_alpha_prod(t))
clip_coeff = torch.sqrt(scheduler.get_alpha_prod(t - 1)) * scheduler.get_beta(t) / (1 - scheduler.get_alpha_prod(t))
# ii) predict noise residual
with torch.no_grad():
noise_residual = model(image, t)
# iii) compute predicted image from residual
# See 2nd formula at https://github.com/hojonathanho/diffusion/issues/5#issue-896554416 for comparison
pred_mean = clip_image_coeff * image - clip_noise_coeff * noise_residual
pred_mean = torch.clamp(pred_mean, -1, 1)
prev_image = clip_coeff * pred_mean + image_coeff * image
# iv) sample variance
prev_variance = scheduler.sample_variance(t, prev_image.shape, device=torch_device, generator=generator)
# v) sample x_{t-1} ~ N(prev_image, prev_variance)
sampled_prev_image = prev_image + prev_variance
image = sampled_prev_image
2022-06-06 10:19:02 -06:00
# process image to PIL
2022-06-06 09:43:36 -06:00
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
2022-06-06 10:19:02 -06:00
# save image
2022-06-06 09:43:36 -06:00
image_pil.save("test.png")
2022-06-02 07:59:58 -06:00
```
## 2. `diffusers` as a collection of most import Diffusion models (GLIDE, Dalle, ...)
`models` directory in repository hosts complete diffusion training code & pipelines. Easily load & saveable from the Hub. Will be possible to use just from pip `diffusers` version:
Example:
```python
from modeling_ddpm import DDPM
2022-06-06 10:19:02 -06:00
import PIL.Image
import numpy as np
2022-06-02 07:59:58 -06:00
2022-06-06 10:19:02 -06:00
# load model and scheduler
2022-06-06 10:17:15 -06:00
ddpm = DDPM.from_pretrained("fusing/ddpm-lsun-bedroom-pipe")
2022-06-06 10:19:02 -06:00
# run pipeline in inference (sample random noise and denoise)
2022-06-02 07:59:58 -06:00
image = ddpm()
2022-06-06 10:19:02 -06:00
# process image to PIL
2022-06-06 10:17:15 -06:00
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
2022-06-06 10:19:02 -06:00
# save image
2022-06-06 10:17:15 -06:00
image_pil.save("test.png")
2022-06-02 07:59:58 -06:00
```
2022-06-01 16:42:08 -06:00
## Library structure:
```
├── models
2022-06-01 16:50:23 -06:00
│ ├── audio
│ │ └── fastdiff
│ │ ├── modeling_fastdiff.py
│ │ ├── README.md
│ │ └── run_fastdiff.py
│ └── vision
│ ├── dalle2
│ │ ├── modeling_dalle2.py
│ │ ├── README.md
│ │ └── run_dalle2.py
│ ├── ddpm
│ │ ├── modeling_ddpm.py
│ │ ├── README.md
│ │ └── run_ddpm.py
│ ├── glide
│ │ ├── modeling_glide.py
│ │ ├── README.md
│ │ └── run_dalle2.py
│ ├── imagen
│ │ ├── modeling_dalle2.py
│ │ ├── README.md
│ │ └── run_dalle2.py
│ └── latent_diffusion
│ ├── modeling_latent_diffusion.py
│ ├── README.md
│ └── run_latent_diffusion.py
2022-06-01 16:42:08 -06:00
├── src
│ └── diffusers
│ ├── configuration_utils.py
│ ├── __init__ .py
│ ├── modeling_utils.py
│ ├── models
│ │ └── unet.py
│ ├── processors
2022-06-06 09:43:36 -06:00
│ └── schedulers
│ ├── gaussian_ddpm.py
2022-06-01 16:42:08 -06:00
├── tests
│ └── test_modeling_utils.py
```