Music Spectrogram diffusion pipeline (#1044)
* initial TokenEncoder and ContinuousEncoder * initial modules * added ContinuousContextTransformer * fix copy paste error * use numpy for get_sequence_length * initial terminal relative positional encodings * fix weights keys * fix assert * cross attend style: concat encodings * make style * concat once * fix formatting * Initial SpectrogramPipeline * fix input_tokens * make style * added mel output * ignore weights for config * move mel to numpy * import pipeline * fix class names and import * moved models to models folder * import ContinuousContextTransformer and SpectrogramDiffusionPipeline * initial spec diffusion converstion script * renamed config to t5config * added weight loading * use arguments instead of t5config * broadcast noise time to batch dim * fix call * added scale_to_features * fix weights * transpose laynorm weight * scale is a vector * scale the query outputs * added comment * undo scaling * undo depth_scaling * inital get_extended_attention_mask * attention_mask is none in self-attention * cleanup * manually invert attention * nn.linear need bias=False * added T5LayerFFCond * remove to fix conflict * make style and dummy * remove unsed variables * remove predict_epsilon * Move accelerate to a soft-dependency (#1134) * finish * finish * Update src/diffusers/modeling_utils.py * Update src/diffusers/pipeline_utils.py Co-authored-by: Anton Lozhkov <anton@huggingface.co> * more fixes * fix Co-authored-by: Anton Lozhkov <anton@huggingface.co> * fix order * added initial midi to note token data pipeline * added int to int tokenizer * remove duplicate * added logic for segments * add melgan to pipeline * move autoregressive gen into pipeline * added note_representation_processor_chain * fix dtypes * remove immutabledict req * initial doc * use np.where * require note_seq * fix typo * update dependency * added note-seq to test * added is_note_seq_available * fix import * added toc * added example usage * undo for now * moved docs * fix merge * fix imports * predict first segment * avoid un-needed copy to and from cpu * make style * Copyright * fix style * add test and fix inference steps * remove bogus files * reorder models * up * remove transformers dependency * make work with diffusers cross attention * clean more * remove @ * improve further * up * uP * Apply suggestions from code review * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py * loop over all tokens * make style * Added a section on the model * fix formatting * grammer * formatting * make fix-copies * Update src/diffusers/pipelines/__init__.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * added callback ad optional ionnx * do not squeeze batch dim * clean up more * upload * convert jax to nnumpy * make style * fix warning * make fix-copies * fix warning * add initial fast tests * add initial pipeline_params * eval mode due to dropout * skip batch tests as pipeline runs on a single file * make style * fix relative path * fix doc tests * Update src/diffusers/models/t5_film_transformer.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update src/diffusers/models/t5_film_transformer.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update docs/source/en/api/pipelines/spectrogram_diffusion.mdx Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> * add MidiProcessor * format * fix org * Apply suggestions from code review * Update tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py * make style * pin protobuf to <4 * fix formatting * white space * tensorboard needs protobuf --------- Co-authored-by: Patrick von Platen <patrick.v.platen@gmail.com> Co-authored-by: Anton Lozhkov <anton@huggingface.co>
This commit is contained in:
parent
14e3a28c12
commit
2ef9bdd76f
|
|
@ -158,6 +158,8 @@
|
|||
title: Score SDE VE
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- local: api/pipelines/spectrogram_diffusion
|
||||
title: "Spectrogram Diffusion"
|
||||
- sections:
|
||||
- local: api/pipelines/stable_diffusion/overview
|
||||
title: Overview
|
||||
|
|
|
|||
|
|
@ -0,0 +1,54 @@
|
|||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Multi-instrument Music Synthesis with Spectrogram Diffusion
|
||||
|
||||
## Overview
|
||||
|
||||
[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
|
||||
|
||||
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
|
||||
|
||||
The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
|
||||
|
||||
## Model
|
||||
|
||||
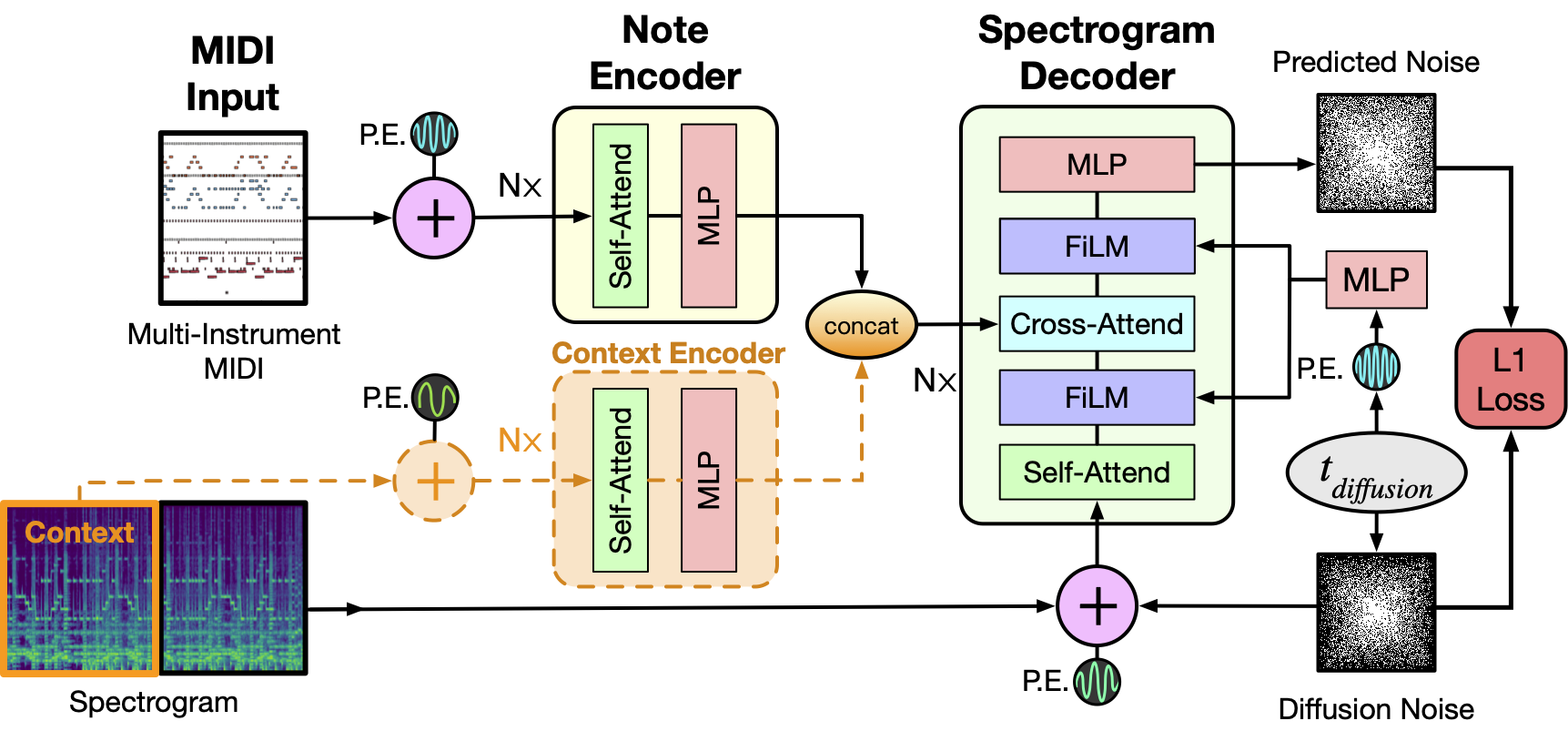
|
||||
|
||||
As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Colab
|
||||
|---|---|:---:|
|
||||
| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
|
||||
|
||||
|
||||
## Example usage
|
||||
|
||||
```python
|
||||
from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
|
||||
|
||||
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
|
||||
pipe = pipe.to("cuda")
|
||||
processor = MidiProcessor()
|
||||
|
||||
# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
|
||||
output = pipe(processor("beethoven_hammerklavier_2.mid"))
|
||||
|
||||
audio = output.audios[0]
|
||||
```
|
||||
|
||||
## SpectrogramDiffusionPipeline
|
||||
[[autodoc]] SpectrogramDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
|
@ -0,0 +1,213 @@
|
|||
#!/usr/bin/env python3
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import jax as jnp
|
||||
import numpy as onp
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from music_spectrogram_diffusion import inference
|
||||
from t5x import checkpoints
|
||||
|
||||
from diffusers import DDPMScheduler, OnnxRuntimeModel, SpectrogramDiffusionPipeline
|
||||
from diffusers.pipelines.spectrogram_diffusion import SpectrogramContEncoder, SpectrogramNotesEncoder, T5FilmDecoder
|
||||
|
||||
|
||||
MODEL = "base_with_context"
|
||||
|
||||
|
||||
def load_notes_encoder(weights, model):
|
||||
model.token_embedder.weight = nn.Parameter(torch.FloatTensor(weights["token_embedder"]["embedding"]))
|
||||
model.position_encoding.weight = nn.Parameter(
|
||||
torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
|
||||
)
|
||||
for lyr_num, lyr in enumerate(model.encoders):
|
||||
ly_weight = weights[f"layers_{lyr_num}"]
|
||||
lyr.layer[0].layer_norm.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"])
|
||||
)
|
||||
|
||||
attention_weights = ly_weight["attention"]
|
||||
lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
|
||||
|
||||
lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
|
||||
|
||||
lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
|
||||
lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
|
||||
lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
|
||||
|
||||
model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"]))
|
||||
return model
|
||||
|
||||
|
||||
def load_continuous_encoder(weights, model):
|
||||
model.input_proj.weight = nn.Parameter(torch.FloatTensor(weights["input_proj"]["kernel"].T))
|
||||
|
||||
model.position_encoding.weight = nn.Parameter(
|
||||
torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
|
||||
)
|
||||
|
||||
for lyr_num, lyr in enumerate(model.encoders):
|
||||
ly_weight = weights[f"layers_{lyr_num}"]
|
||||
attention_weights = ly_weight["attention"]
|
||||
|
||||
lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
|
||||
lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
|
||||
lyr.layer[0].layer_norm.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"])
|
||||
)
|
||||
|
||||
lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
|
||||
lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
|
||||
lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
|
||||
lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
|
||||
|
||||
model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"]))
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def load_decoder(weights, model):
|
||||
model.conditioning_emb[0].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense0"]["kernel"].T))
|
||||
model.conditioning_emb[2].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense1"]["kernel"].T))
|
||||
|
||||
model.position_encoding.weight = nn.Parameter(
|
||||
torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
|
||||
)
|
||||
|
||||
model.continuous_inputs_projection.weight = nn.Parameter(
|
||||
torch.FloatTensor(weights["continuous_inputs_projection"]["kernel"].T)
|
||||
)
|
||||
|
||||
for lyr_num, lyr in enumerate(model.decoders):
|
||||
ly_weight = weights[f"layers_{lyr_num}"]
|
||||
lyr.layer[0].layer_norm.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["pre_self_attention_layer_norm"]["scale"])
|
||||
)
|
||||
|
||||
lyr.layer[0].FiLMLayer.scale_bias.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["FiLMLayer_0"]["DenseGeneral_0"]["kernel"].T)
|
||||
)
|
||||
|
||||
attention_weights = ly_weight["self_attention"]
|
||||
lyr.layer[0].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
|
||||
lyr.layer[0].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
|
||||
lyr.layer[0].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
|
||||
lyr.layer[0].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
|
||||
|
||||
attention_weights = ly_weight["MultiHeadDotProductAttention_0"]
|
||||
lyr.layer[1].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
|
||||
lyr.layer[1].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
|
||||
lyr.layer[1].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
|
||||
lyr.layer[1].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
|
||||
lyr.layer[1].layer_norm.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["pre_cross_attention_layer_norm"]["scale"])
|
||||
)
|
||||
|
||||
lyr.layer[2].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
|
||||
lyr.layer[2].film.scale_bias.weight = nn.Parameter(
|
||||
torch.FloatTensor(ly_weight["FiLMLayer_1"]["DenseGeneral_0"]["kernel"].T)
|
||||
)
|
||||
lyr.layer[2].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
|
||||
lyr.layer[2].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
|
||||
lyr.layer[2].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
|
||||
|
||||
model.decoder_norm.weight = nn.Parameter(torch.FloatTensor(weights["decoder_norm"]["scale"]))
|
||||
|
||||
model.spec_out.weight = nn.Parameter(torch.FloatTensor(weights["spec_out_dense"]["kernel"].T))
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def main(args):
|
||||
t5_checkpoint = checkpoints.load_t5x_checkpoint(args.checkpoint_path)
|
||||
t5_checkpoint = jnp.tree_util.tree_map(onp.array, t5_checkpoint)
|
||||
|
||||
gin_overrides = [
|
||||
"from __gin__ import dynamic_registration",
|
||||
"from music_spectrogram_diffusion.models.diffusion import diffusion_utils",
|
||||
"diffusion_utils.ClassifierFreeGuidanceConfig.eval_condition_weight = 2.0",
|
||||
"diffusion_utils.DiffusionConfig.classifier_free_guidance = @diffusion_utils.ClassifierFreeGuidanceConfig()",
|
||||
]
|
||||
|
||||
gin_file = os.path.join(args.checkpoint_path, "..", "config.gin")
|
||||
gin_config = inference.parse_training_gin_file(gin_file, gin_overrides)
|
||||
synth_model = inference.InferenceModel(args.checkpoint_path, gin_config)
|
||||
|
||||
scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", variance_type="fixed_large")
|
||||
|
||||
notes_encoder = SpectrogramNotesEncoder(
|
||||
max_length=synth_model.sequence_length["inputs"],
|
||||
vocab_size=synth_model.model.module.config.vocab_size,
|
||||
d_model=synth_model.model.module.config.emb_dim,
|
||||
dropout_rate=synth_model.model.module.config.dropout_rate,
|
||||
num_layers=synth_model.model.module.config.num_encoder_layers,
|
||||
num_heads=synth_model.model.module.config.num_heads,
|
||||
d_kv=synth_model.model.module.config.head_dim,
|
||||
d_ff=synth_model.model.module.config.mlp_dim,
|
||||
feed_forward_proj="gated-gelu",
|
||||
)
|
||||
|
||||
continuous_encoder = SpectrogramContEncoder(
|
||||
input_dims=synth_model.audio_codec.n_dims,
|
||||
targets_context_length=synth_model.sequence_length["targets_context"],
|
||||
d_model=synth_model.model.module.config.emb_dim,
|
||||
dropout_rate=synth_model.model.module.config.dropout_rate,
|
||||
num_layers=synth_model.model.module.config.num_encoder_layers,
|
||||
num_heads=synth_model.model.module.config.num_heads,
|
||||
d_kv=synth_model.model.module.config.head_dim,
|
||||
d_ff=synth_model.model.module.config.mlp_dim,
|
||||
feed_forward_proj="gated-gelu",
|
||||
)
|
||||
|
||||
decoder = T5FilmDecoder(
|
||||
input_dims=synth_model.audio_codec.n_dims,
|
||||
targets_length=synth_model.sequence_length["targets_context"],
|
||||
max_decoder_noise_time=synth_model.model.module.config.max_decoder_noise_time,
|
||||
d_model=synth_model.model.module.config.emb_dim,
|
||||
num_layers=synth_model.model.module.config.num_decoder_layers,
|
||||
num_heads=synth_model.model.module.config.num_heads,
|
||||
d_kv=synth_model.model.module.config.head_dim,
|
||||
d_ff=synth_model.model.module.config.mlp_dim,
|
||||
dropout_rate=synth_model.model.module.config.dropout_rate,
|
||||
)
|
||||
|
||||
notes_encoder = load_notes_encoder(t5_checkpoint["target"]["token_encoder"], notes_encoder)
|
||||
continuous_encoder = load_continuous_encoder(t5_checkpoint["target"]["continuous_encoder"], continuous_encoder)
|
||||
decoder = load_decoder(t5_checkpoint["target"]["decoder"], decoder)
|
||||
|
||||
melgan = OnnxRuntimeModel.from_pretrained("kashif/soundstream_mel_decoder")
|
||||
|
||||
pipe = SpectrogramDiffusionPipeline(
|
||||
notes_encoder=notes_encoder,
|
||||
continuous_encoder=continuous_encoder,
|
||||
decoder=decoder,
|
||||
scheduler=scheduler,
|
||||
melgan=melgan,
|
||||
)
|
||||
if args.save:
|
||||
pipe.save_pretrained(args.output_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("--output_path", default=None, type=str, required=True, help="Path to the converted model.")
|
||||
parser.add_argument(
|
||||
"--save", default=True, type=bool, required=False, help="Whether to save the converted model or not."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--checkpoint_path",
|
||||
default=f"{MODEL}/checkpoint_500000",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to the original jax model checkpoint.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
5
setup.py
5
setup.py
|
|
@ -95,8 +95,10 @@ _deps = [
|
|||
"Jinja2",
|
||||
"k-diffusion>=0.0.12",
|
||||
"librosa",
|
||||
"note-seq",
|
||||
"numpy",
|
||||
"parameterized",
|
||||
"protobuf>=3.20.3,<4",
|
||||
"pytest",
|
||||
"pytest-timeout",
|
||||
"pytest-xdist",
|
||||
|
|
@ -182,13 +184,14 @@ extras = {}
|
|||
extras = {}
|
||||
extras["quality"] = deps_list("black", "isort", "ruff", "hf-doc-builder")
|
||||
extras["docs"] = deps_list("hf-doc-builder")
|
||||
extras["training"] = deps_list("accelerate", "datasets", "tensorboard", "Jinja2")
|
||||
extras["training"] = deps_list("accelerate", "datasets", "protobuf", "tensorboard", "Jinja2")
|
||||
extras["test"] = deps_list(
|
||||
"compel",
|
||||
"datasets",
|
||||
"Jinja2",
|
||||
"k-diffusion",
|
||||
"librosa",
|
||||
"note-seq",
|
||||
"parameterized",
|
||||
"pytest",
|
||||
"pytest-timeout",
|
||||
|
|
|
|||
|
|
@ -8,6 +8,7 @@ from .utils import (
|
|||
is_k_diffusion_available,
|
||||
is_k_diffusion_version,
|
||||
is_librosa_available,
|
||||
is_note_seq_available,
|
||||
is_onnx_available,
|
||||
is_scipy_available,
|
||||
is_torch_available,
|
||||
|
|
@ -37,6 +38,7 @@ else:
|
|||
ControlNetModel,
|
||||
ModelMixin,
|
||||
PriorTransformer,
|
||||
T5FilmDecoder,
|
||||
Transformer2DModel,
|
||||
UNet1DModel,
|
||||
UNet2DConditionModel,
|
||||
|
|
@ -172,6 +174,14 @@ except OptionalDependencyNotAvailable:
|
|||
else:
|
||||
from .pipelines import AudioDiffusionPipeline, Mel
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from .utils.dummy_torch_and_note_seq_objects import * # noqa F403
|
||||
else:
|
||||
from .pipelines import SpectrogramDiffusionPipeline
|
||||
|
||||
try:
|
||||
if not is_flax_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
|
|
@ -205,3 +215,11 @@ else:
|
|||
FlaxStableDiffusionInpaintPipeline,
|
||||
FlaxStableDiffusionPipeline,
|
||||
)
|
||||
|
||||
try:
|
||||
if not (is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from .utils.dummy_note_seq_objects import * # noqa F403
|
||||
else:
|
||||
from .pipelines import MidiProcessor
|
||||
|
|
|
|||
|
|
@ -19,8 +19,10 @@ deps = {
|
|||
"Jinja2": "Jinja2",
|
||||
"k-diffusion": "k-diffusion>=0.0.12",
|
||||
"librosa": "librosa",
|
||||
"note-seq": "note-seq",
|
||||
"numpy": "numpy",
|
||||
"parameterized": "parameterized",
|
||||
"protobuf": "protobuf>=3.20.3,<4",
|
||||
"pytest": "pytest",
|
||||
"pytest-timeout": "pytest-timeout",
|
||||
"pytest-xdist": "pytest-xdist",
|
||||
|
|
|
|||
|
|
@ -21,6 +21,7 @@ if is_torch_available():
|
|||
from .dual_transformer_2d import DualTransformer2DModel
|
||||
from .modeling_utils import ModelMixin
|
||||
from .prior_transformer import PriorTransformer
|
||||
from .t5_film_transformer import T5FilmDecoder
|
||||
from .transformer_2d import Transformer2DModel
|
||||
from .unet_1d import UNet1DModel
|
||||
from .unet_2d import UNet2DModel
|
||||
|
|
|
|||
|
|
@ -0,0 +1,321 @@
|
|||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import math
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .attention_processor import Attention
|
||||
from .embeddings import get_timestep_embedding
|
||||
from .modeling_utils import ModelMixin
|
||||
|
||||
|
||||
class T5FilmDecoder(ModelMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
input_dims: int = 128,
|
||||
targets_length: int = 256,
|
||||
max_decoder_noise_time: float = 2000.0,
|
||||
d_model: int = 768,
|
||||
num_layers: int = 12,
|
||||
num_heads: int = 12,
|
||||
d_kv: int = 64,
|
||||
d_ff: int = 2048,
|
||||
dropout_rate: float = 0.1,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.conditioning_emb = nn.Sequential(
|
||||
nn.Linear(d_model, d_model * 4, bias=False),
|
||||
nn.SiLU(),
|
||||
nn.Linear(d_model * 4, d_model * 4, bias=False),
|
||||
nn.SiLU(),
|
||||
)
|
||||
|
||||
self.position_encoding = nn.Embedding(targets_length, d_model)
|
||||
self.position_encoding.weight.requires_grad = False
|
||||
|
||||
self.continuous_inputs_projection = nn.Linear(input_dims, d_model, bias=False)
|
||||
|
||||
self.dropout = nn.Dropout(p=dropout_rate)
|
||||
|
||||
self.decoders = nn.ModuleList()
|
||||
for lyr_num in range(num_layers):
|
||||
# FiLM conditional T5 decoder
|
||||
lyr = DecoderLayer(d_model=d_model, d_kv=d_kv, num_heads=num_heads, d_ff=d_ff, dropout_rate=dropout_rate)
|
||||
self.decoders.append(lyr)
|
||||
|
||||
self.decoder_norm = T5LayerNorm(d_model)
|
||||
|
||||
self.post_dropout = nn.Dropout(p=dropout_rate)
|
||||
self.spec_out = nn.Linear(d_model, input_dims, bias=False)
|
||||
|
||||
def encoder_decoder_mask(self, query_input, key_input):
|
||||
mask = torch.mul(query_input.unsqueeze(-1), key_input.unsqueeze(-2))
|
||||
return mask.unsqueeze(-3)
|
||||
|
||||
def forward(self, encodings_and_masks, decoder_input_tokens, decoder_noise_time):
|
||||
batch, _, _ = decoder_input_tokens.shape
|
||||
assert decoder_noise_time.shape == (batch,)
|
||||
|
||||
# decoder_noise_time is in [0, 1), so rescale to expected timing range.
|
||||
time_steps = get_timestep_embedding(
|
||||
decoder_noise_time * self.config.max_decoder_noise_time,
|
||||
embedding_dim=self.config.d_model,
|
||||
max_period=self.config.max_decoder_noise_time,
|
||||
).to(dtype=self.dtype)
|
||||
|
||||
conditioning_emb = self.conditioning_emb(time_steps).unsqueeze(1)
|
||||
|
||||
assert conditioning_emb.shape == (batch, 1, self.config.d_model * 4)
|
||||
|
||||
seq_length = decoder_input_tokens.shape[1]
|
||||
|
||||
# If we want to use relative positions for audio context, we can just offset
|
||||
# this sequence by the length of encodings_and_masks.
|
||||
decoder_positions = torch.broadcast_to(
|
||||
torch.arange(seq_length, device=decoder_input_tokens.device),
|
||||
(batch, seq_length),
|
||||
)
|
||||
|
||||
position_encodings = self.position_encoding(decoder_positions)
|
||||
|
||||
inputs = self.continuous_inputs_projection(decoder_input_tokens)
|
||||
inputs += position_encodings
|
||||
y = self.dropout(inputs)
|
||||
|
||||
# decoder: No padding present.
|
||||
decoder_mask = torch.ones(
|
||||
decoder_input_tokens.shape[:2], device=decoder_input_tokens.device, dtype=inputs.dtype
|
||||
)
|
||||
|
||||
# Translate encoding masks to encoder-decoder masks.
|
||||
encodings_and_encdec_masks = [(x, self.encoder_decoder_mask(decoder_mask, y)) for x, y in encodings_and_masks]
|
||||
|
||||
# cross attend style: concat encodings
|
||||
encoded = torch.cat([x[0] for x in encodings_and_encdec_masks], dim=1)
|
||||
encoder_decoder_mask = torch.cat([x[1] for x in encodings_and_encdec_masks], dim=-1)
|
||||
|
||||
for lyr in self.decoders:
|
||||
y = lyr(
|
||||
y,
|
||||
conditioning_emb=conditioning_emb,
|
||||
encoder_hidden_states=encoded,
|
||||
encoder_attention_mask=encoder_decoder_mask,
|
||||
)[0]
|
||||
|
||||
y = self.decoder_norm(y)
|
||||
y = self.post_dropout(y)
|
||||
|
||||
spec_out = self.spec_out(y)
|
||||
return spec_out
|
||||
|
||||
|
||||
class DecoderLayer(nn.Module):
|
||||
def __init__(self, d_model, d_kv, num_heads, d_ff, dropout_rate, layer_norm_epsilon=1e-6):
|
||||
super().__init__()
|
||||
self.layer = nn.ModuleList()
|
||||
|
||||
# cond self attention: layer 0
|
||||
self.layer.append(
|
||||
T5LayerSelfAttentionCond(d_model=d_model, d_kv=d_kv, num_heads=num_heads, dropout_rate=dropout_rate)
|
||||
)
|
||||
|
||||
# cross attention: layer 1
|
||||
self.layer.append(
|
||||
T5LayerCrossAttention(
|
||||
d_model=d_model,
|
||||
d_kv=d_kv,
|
||||
num_heads=num_heads,
|
||||
dropout_rate=dropout_rate,
|
||||
layer_norm_epsilon=layer_norm_epsilon,
|
||||
)
|
||||
)
|
||||
|
||||
# Film Cond MLP + dropout: last layer
|
||||
self.layer.append(
|
||||
T5LayerFFCond(d_model=d_model, d_ff=d_ff, dropout_rate=dropout_rate, layer_norm_epsilon=layer_norm_epsilon)
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states,
|
||||
conditioning_emb=None,
|
||||
attention_mask=None,
|
||||
encoder_hidden_states=None,
|
||||
encoder_attention_mask=None,
|
||||
encoder_decoder_position_bias=None,
|
||||
):
|
||||
hidden_states = self.layer[0](
|
||||
hidden_states,
|
||||
conditioning_emb=conditioning_emb,
|
||||
attention_mask=attention_mask,
|
||||
)
|
||||
|
||||
if encoder_hidden_states is not None:
|
||||
encoder_extended_attention_mask = torch.where(encoder_attention_mask > 0, 0, -1e10).to(
|
||||
encoder_hidden_states.dtype
|
||||
)
|
||||
|
||||
hidden_states = self.layer[1](
|
||||
hidden_states,
|
||||
key_value_states=encoder_hidden_states,
|
||||
attention_mask=encoder_extended_attention_mask,
|
||||
)
|
||||
|
||||
# Apply Film Conditional Feed Forward layer
|
||||
hidden_states = self.layer[-1](hidden_states, conditioning_emb)
|
||||
|
||||
return (hidden_states,)
|
||||
|
||||
|
||||
class T5LayerSelfAttentionCond(nn.Module):
|
||||
def __init__(self, d_model, d_kv, num_heads, dropout_rate):
|
||||
super().__init__()
|
||||
self.layer_norm = T5LayerNorm(d_model)
|
||||
self.FiLMLayer = T5FiLMLayer(in_features=d_model * 4, out_features=d_model)
|
||||
self.attention = Attention(query_dim=d_model, heads=num_heads, dim_head=d_kv, out_bias=False, scale_qk=False)
|
||||
self.dropout = nn.Dropout(dropout_rate)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states,
|
||||
conditioning_emb=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
# pre_self_attention_layer_norm
|
||||
normed_hidden_states = self.layer_norm(hidden_states)
|
||||
|
||||
if conditioning_emb is not None:
|
||||
normed_hidden_states = self.FiLMLayer(normed_hidden_states, conditioning_emb)
|
||||
|
||||
# Self-attention block
|
||||
attention_output = self.attention(normed_hidden_states)
|
||||
|
||||
hidden_states = hidden_states + self.dropout(attention_output)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class T5LayerCrossAttention(nn.Module):
|
||||
def __init__(self, d_model, d_kv, num_heads, dropout_rate, layer_norm_epsilon):
|
||||
super().__init__()
|
||||
self.attention = Attention(query_dim=d_model, heads=num_heads, dim_head=d_kv, out_bias=False, scale_qk=False)
|
||||
self.layer_norm = T5LayerNorm(d_model, eps=layer_norm_epsilon)
|
||||
self.dropout = nn.Dropout(dropout_rate)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states,
|
||||
key_value_states=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
normed_hidden_states = self.layer_norm(hidden_states)
|
||||
attention_output = self.attention(
|
||||
normed_hidden_states,
|
||||
encoder_hidden_states=key_value_states,
|
||||
attention_mask=attention_mask.squeeze(1),
|
||||
)
|
||||
layer_output = hidden_states + self.dropout(attention_output)
|
||||
return layer_output
|
||||
|
||||
|
||||
class T5LayerFFCond(nn.Module):
|
||||
def __init__(self, d_model, d_ff, dropout_rate, layer_norm_epsilon):
|
||||
super().__init__()
|
||||
self.DenseReluDense = T5DenseGatedActDense(d_model=d_model, d_ff=d_ff, dropout_rate=dropout_rate)
|
||||
self.film = T5FiLMLayer(in_features=d_model * 4, out_features=d_model)
|
||||
self.layer_norm = T5LayerNorm(d_model, eps=layer_norm_epsilon)
|
||||
self.dropout = nn.Dropout(dropout_rate)
|
||||
|
||||
def forward(self, hidden_states, conditioning_emb=None):
|
||||
forwarded_states = self.layer_norm(hidden_states)
|
||||
if conditioning_emb is not None:
|
||||
forwarded_states = self.film(forwarded_states, conditioning_emb)
|
||||
|
||||
forwarded_states = self.DenseReluDense(forwarded_states)
|
||||
hidden_states = hidden_states + self.dropout(forwarded_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class T5DenseGatedActDense(nn.Module):
|
||||
def __init__(self, d_model, d_ff, dropout_rate):
|
||||
super().__init__()
|
||||
self.wi_0 = nn.Linear(d_model, d_ff, bias=False)
|
||||
self.wi_1 = nn.Linear(d_model, d_ff, bias=False)
|
||||
self.wo = nn.Linear(d_ff, d_model, bias=False)
|
||||
self.dropout = nn.Dropout(dropout_rate)
|
||||
self.act = NewGELUActivation()
|
||||
|
||||
def forward(self, hidden_states):
|
||||
hidden_gelu = self.act(self.wi_0(hidden_states))
|
||||
hidden_linear = self.wi_1(hidden_states)
|
||||
hidden_states = hidden_gelu * hidden_linear
|
||||
hidden_states = self.dropout(hidden_states)
|
||||
|
||||
hidden_states = self.wo(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class T5LayerNorm(nn.Module):
|
||||
def __init__(self, hidden_size, eps=1e-6):
|
||||
"""
|
||||
Construct a layernorm module in the T5 style. No bias and no subtraction of mean.
|
||||
"""
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
self.variance_epsilon = eps
|
||||
|
||||
def forward(self, hidden_states):
|
||||
# T5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
|
||||
# Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
|
||||
# w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
|
||||
# half-precision inputs is done in fp32
|
||||
|
||||
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
||||
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
||||
|
||||
# convert into half-precision if necessary
|
||||
if self.weight.dtype in [torch.float16, torch.bfloat16]:
|
||||
hidden_states = hidden_states.to(self.weight.dtype)
|
||||
|
||||
return self.weight * hidden_states
|
||||
|
||||
|
||||
class NewGELUActivation(nn.Module):
|
||||
"""
|
||||
Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
|
||||
the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
|
||||
"""
|
||||
|
||||
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
||||
return 0.5 * input * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (input + 0.044715 * torch.pow(input, 3.0))))
|
||||
|
||||
|
||||
class T5FiLMLayer(nn.Module):
|
||||
"""
|
||||
FiLM Layer
|
||||
"""
|
||||
|
||||
def __init__(self, in_features, out_features):
|
||||
super().__init__()
|
||||
self.scale_bias = nn.Linear(in_features, out_features * 2, bias=False)
|
||||
|
||||
def forward(self, x, conditioning_emb):
|
||||
emb = self.scale_bias(conditioning_emb)
|
||||
scale, shift = torch.chunk(emb, 2, -1)
|
||||
x = x * (1 + scale) + shift
|
||||
return x
|
||||
|
|
@ -3,6 +3,7 @@ from ..utils import (
|
|||
is_flax_available,
|
||||
is_k_diffusion_available,
|
||||
is_librosa_available,
|
||||
is_note_seq_available,
|
||||
is_onnx_available,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
|
|
@ -25,6 +26,7 @@ else:
|
|||
from .pndm import PNDMPipeline
|
||||
from .repaint import RePaintPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
from .spectrogram_diffusion import SpectrogramDiffusionPipeline
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
|
||||
try:
|
||||
|
|
@ -126,3 +128,10 @@ else:
|
|||
FlaxStableDiffusionInpaintPipeline,
|
||||
FlaxStableDiffusionPipeline,
|
||||
)
|
||||
try:
|
||||
if not (is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_note_seq_objects import * # noqa F403
|
||||
else:
|
||||
from .spectrogram_diffusion import MidiProcessor
|
||||
|
|
|
|||
|
|
@ -0,0 +1,13 @@
|
|||
# flake8: noqa
|
||||
from ...utils import is_note_seq_available
|
||||
|
||||
from .notes_encoder import SpectrogramNotesEncoder
|
||||
from .continous_encoder import SpectrogramContEncoder
|
||||
from .pipeline_spectrogram_diffusion import (
|
||||
SpectrogramContEncoder,
|
||||
SpectrogramDiffusionPipeline,
|
||||
T5FilmDecoder,
|
||||
)
|
||||
|
||||
if is_note_seq_available():
|
||||
from .midi_utils import MidiProcessor
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
# Copyright 2022 The Music Spectrogram Diffusion Authors.
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from transformers.modeling_utils import ModuleUtilsMixin
|
||||
from transformers.models.t5.modeling_t5 import (
|
||||
T5Block,
|
||||
T5Config,
|
||||
T5LayerNorm,
|
||||
)
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramContEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
input_dims: int,
|
||||
targets_context_length: int,
|
||||
d_model: int,
|
||||
dropout_rate: float,
|
||||
num_layers: int,
|
||||
num_heads: int,
|
||||
d_kv: int,
|
||||
d_ff: int,
|
||||
feed_forward_proj: str,
|
||||
is_decoder: bool = False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.input_proj = nn.Linear(input_dims, d_model, bias=False)
|
||||
|
||||
self.position_encoding = nn.Embedding(targets_context_length, d_model)
|
||||
self.position_encoding.weight.requires_grad = False
|
||||
|
||||
self.dropout_pre = nn.Dropout(p=dropout_rate)
|
||||
|
||||
t5config = T5Config(
|
||||
d_model=d_model,
|
||||
num_heads=num_heads,
|
||||
d_kv=d_kv,
|
||||
d_ff=d_ff,
|
||||
feed_forward_proj=feed_forward_proj,
|
||||
dropout_rate=dropout_rate,
|
||||
is_decoder=is_decoder,
|
||||
is_encoder_decoder=False,
|
||||
)
|
||||
self.encoders = nn.ModuleList()
|
||||
for lyr_num in range(num_layers):
|
||||
lyr = T5Block(t5config)
|
||||
self.encoders.append(lyr)
|
||||
|
||||
self.layer_norm = T5LayerNorm(d_model)
|
||||
self.dropout_post = nn.Dropout(p=dropout_rate)
|
||||
|
||||
def forward(self, encoder_inputs, encoder_inputs_mask):
|
||||
x = self.input_proj(encoder_inputs)
|
||||
|
||||
# terminal relative positional encodings
|
||||
max_positions = encoder_inputs.shape[1]
|
||||
input_positions = torch.arange(max_positions, device=encoder_inputs.device)
|
||||
|
||||
seq_lens = encoder_inputs_mask.sum(-1)
|
||||
input_positions = torch.roll(input_positions.unsqueeze(0), tuple(seq_lens.tolist()), dims=0)
|
||||
x += self.position_encoding(input_positions)
|
||||
|
||||
x = self.dropout_pre(x)
|
||||
|
||||
# inverted the attention mask
|
||||
input_shape = encoder_inputs.size()
|
||||
extended_attention_mask = self.get_extended_attention_mask(encoder_inputs_mask, input_shape)
|
||||
|
||||
for lyr in self.encoders:
|
||||
x = lyr(x, extended_attention_mask)[0]
|
||||
x = self.layer_norm(x)
|
||||
|
||||
return self.dropout_post(x), encoder_inputs_mask
|
||||
|
|
@ -0,0 +1,667 @@
|
|||
# Copyright 2022 The Music Spectrogram Diffusion Authors.
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import dataclasses
|
||||
import math
|
||||
import os
|
||||
from typing import Any, Callable, List, Mapping, MutableMapping, Optional, Sequence, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ...utils import is_note_seq_available
|
||||
from .pipeline_spectrogram_diffusion import TARGET_FEATURE_LENGTH
|
||||
|
||||
|
||||
if is_note_seq_available():
|
||||
import note_seq
|
||||
else:
|
||||
raise ImportError("Please install note-seq via `pip install note-seq`")
|
||||
|
||||
|
||||
INPUT_FEATURE_LENGTH = 2048
|
||||
|
||||
SAMPLE_RATE = 16000
|
||||
HOP_SIZE = 320
|
||||
FRAME_RATE = int(SAMPLE_RATE // HOP_SIZE)
|
||||
|
||||
DEFAULT_STEPS_PER_SECOND = 100
|
||||
DEFAULT_MAX_SHIFT_SECONDS = 10
|
||||
DEFAULT_NUM_VELOCITY_BINS = 1
|
||||
|
||||
SLAKH_CLASS_PROGRAMS = {
|
||||
"Acoustic Piano": 0,
|
||||
"Electric Piano": 4,
|
||||
"Chromatic Percussion": 8,
|
||||
"Organ": 16,
|
||||
"Acoustic Guitar": 24,
|
||||
"Clean Electric Guitar": 26,
|
||||
"Distorted Electric Guitar": 29,
|
||||
"Acoustic Bass": 32,
|
||||
"Electric Bass": 33,
|
||||
"Violin": 40,
|
||||
"Viola": 41,
|
||||
"Cello": 42,
|
||||
"Contrabass": 43,
|
||||
"Orchestral Harp": 46,
|
||||
"Timpani": 47,
|
||||
"String Ensemble": 48,
|
||||
"Synth Strings": 50,
|
||||
"Choir and Voice": 52,
|
||||
"Orchestral Hit": 55,
|
||||
"Trumpet": 56,
|
||||
"Trombone": 57,
|
||||
"Tuba": 58,
|
||||
"French Horn": 60,
|
||||
"Brass Section": 61,
|
||||
"Soprano/Alto Sax": 64,
|
||||
"Tenor Sax": 66,
|
||||
"Baritone Sax": 67,
|
||||
"Oboe": 68,
|
||||
"English Horn": 69,
|
||||
"Bassoon": 70,
|
||||
"Clarinet": 71,
|
||||
"Pipe": 73,
|
||||
"Synth Lead": 80,
|
||||
"Synth Pad": 88,
|
||||
}
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class NoteRepresentationConfig:
|
||||
"""Configuration note representations."""
|
||||
|
||||
onsets_only: bool
|
||||
include_ties: bool
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class NoteEventData:
|
||||
pitch: int
|
||||
velocity: Optional[int] = None
|
||||
program: Optional[int] = None
|
||||
is_drum: Optional[bool] = None
|
||||
instrument: Optional[int] = None
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class NoteEncodingState:
|
||||
"""Encoding state for note transcription, keeping track of active pitches."""
|
||||
|
||||
# velocity bin for active pitches and programs
|
||||
active_pitches: MutableMapping[Tuple[int, int], int] = dataclasses.field(default_factory=dict)
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class EventRange:
|
||||
type: str
|
||||
min_value: int
|
||||
max_value: int
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class Event:
|
||||
type: str
|
||||
value: int
|
||||
|
||||
|
||||
class Tokenizer:
|
||||
def __init__(self, regular_ids: int):
|
||||
# The special tokens: 0=PAD, 1=EOS, and 2=UNK
|
||||
self._num_special_tokens = 3
|
||||
self._num_regular_tokens = regular_ids
|
||||
|
||||
def encode(self, token_ids):
|
||||
encoded = []
|
||||
for token_id in token_ids:
|
||||
if not 0 <= token_id < self._num_regular_tokens:
|
||||
raise ValueError(
|
||||
f"token_id {token_id} does not fall within valid range of [0, {self._num_regular_tokens})"
|
||||
)
|
||||
encoded.append(token_id + self._num_special_tokens)
|
||||
|
||||
# Add EOS token
|
||||
encoded.append(1)
|
||||
|
||||
# Pad to till INPUT_FEATURE_LENGTH
|
||||
encoded = encoded + [0] * (INPUT_FEATURE_LENGTH - len(encoded))
|
||||
|
||||
return encoded
|
||||
|
||||
|
||||
class Codec:
|
||||
"""Encode and decode events.
|
||||
|
||||
Useful for declaring what certain ranges of a vocabulary should be used for. This is intended to be used from
|
||||
Python before encoding or after decoding with GenericTokenVocabulary. This class is more lightweight and does not
|
||||
include things like EOS or UNK token handling.
|
||||
|
||||
To ensure that 'shift' events are always the first block of the vocab and start at 0, that event type is required
|
||||
and specified separately.
|
||||
"""
|
||||
|
||||
def __init__(self, max_shift_steps: int, steps_per_second: float, event_ranges: List[EventRange]):
|
||||
"""Define Codec.
|
||||
|
||||
Args:
|
||||
max_shift_steps: Maximum number of shift steps that can be encoded.
|
||||
steps_per_second: Shift steps will be interpreted as having a duration of
|
||||
1 / steps_per_second.
|
||||
event_ranges: Other supported event types and their ranges.
|
||||
"""
|
||||
self.steps_per_second = steps_per_second
|
||||
self._shift_range = EventRange(type="shift", min_value=0, max_value=max_shift_steps)
|
||||
self._event_ranges = [self._shift_range] + event_ranges
|
||||
# Ensure all event types have unique names.
|
||||
assert len(self._event_ranges) == len(set([er.type for er in self._event_ranges]))
|
||||
|
||||
@property
|
||||
def num_classes(self) -> int:
|
||||
return sum(er.max_value - er.min_value + 1 for er in self._event_ranges)
|
||||
|
||||
# The next couple methods are simplified special case methods just for shift
|
||||
# events that are intended to be used from within autograph functions.
|
||||
|
||||
def is_shift_event_index(self, index: int) -> bool:
|
||||
return (self._shift_range.min_value <= index) and (index <= self._shift_range.max_value)
|
||||
|
||||
@property
|
||||
def max_shift_steps(self) -> int:
|
||||
return self._shift_range.max_value
|
||||
|
||||
def encode_event(self, event: Event) -> int:
|
||||
"""Encode an event to an index."""
|
||||
offset = 0
|
||||
for er in self._event_ranges:
|
||||
if event.type == er.type:
|
||||
if not er.min_value <= event.value <= er.max_value:
|
||||
raise ValueError(
|
||||
f"Event value {event.value} is not within valid range "
|
||||
f"[{er.min_value}, {er.max_value}] for type {event.type}"
|
||||
)
|
||||
return offset + event.value - er.min_value
|
||||
offset += er.max_value - er.min_value + 1
|
||||
|
||||
raise ValueError(f"Unknown event type: {event.type}")
|
||||
|
||||
def event_type_range(self, event_type: str) -> Tuple[int, int]:
|
||||
"""Return [min_id, max_id] for an event type."""
|
||||
offset = 0
|
||||
for er in self._event_ranges:
|
||||
if event_type == er.type:
|
||||
return offset, offset + (er.max_value - er.min_value)
|
||||
offset += er.max_value - er.min_value + 1
|
||||
|
||||
raise ValueError(f"Unknown event type: {event_type}")
|
||||
|
||||
def decode_event_index(self, index: int) -> Event:
|
||||
"""Decode an event index to an Event."""
|
||||
offset = 0
|
||||
for er in self._event_ranges:
|
||||
if offset <= index <= offset + er.max_value - er.min_value:
|
||||
return Event(type=er.type, value=er.min_value + index - offset)
|
||||
offset += er.max_value - er.min_value + 1
|
||||
|
||||
raise ValueError(f"Unknown event index: {index}")
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class ProgramGranularity:
|
||||
# both tokens_map_fn and program_map_fn should be idempotent
|
||||
tokens_map_fn: Callable[[Sequence[int], Codec], Sequence[int]]
|
||||
program_map_fn: Callable[[int], int]
|
||||
|
||||
|
||||
def drop_programs(tokens, codec: Codec):
|
||||
"""Drops program change events from a token sequence."""
|
||||
min_program_id, max_program_id = codec.event_type_range("program")
|
||||
return tokens[(tokens < min_program_id) | (tokens > max_program_id)]
|
||||
|
||||
|
||||
def programs_to_midi_classes(tokens, codec):
|
||||
"""Modifies program events to be the first program in the MIDI class."""
|
||||
min_program_id, max_program_id = codec.event_type_range("program")
|
||||
is_program = (tokens >= min_program_id) & (tokens <= max_program_id)
|
||||
return np.where(is_program, min_program_id + 8 * ((tokens - min_program_id) // 8), tokens)
|
||||
|
||||
|
||||
PROGRAM_GRANULARITIES = {
|
||||
# "flat" granularity; drop program change tokens and set NoteSequence
|
||||
# programs to zero
|
||||
"flat": ProgramGranularity(tokens_map_fn=drop_programs, program_map_fn=lambda program: 0),
|
||||
# map each program to the first program in its MIDI class
|
||||
"midi_class": ProgramGranularity(
|
||||
tokens_map_fn=programs_to_midi_classes, program_map_fn=lambda program: 8 * (program // 8)
|
||||
),
|
||||
# leave programs as is
|
||||
"full": ProgramGranularity(tokens_map_fn=lambda tokens, codec: tokens, program_map_fn=lambda program: program),
|
||||
}
|
||||
|
||||
|
||||
def frame(signal, frame_length, frame_step, pad_end=False, pad_value=0, axis=-1):
|
||||
"""
|
||||
equivalent of tf.signal.frame
|
||||
"""
|
||||
signal_length = signal.shape[axis]
|
||||
if pad_end:
|
||||
frames_overlap = frame_length - frame_step
|
||||
rest_samples = np.abs(signal_length - frames_overlap) % np.abs(frame_length - frames_overlap)
|
||||
pad_size = int(frame_length - rest_samples)
|
||||
|
||||
if pad_size != 0:
|
||||
pad_axis = [0] * signal.ndim
|
||||
pad_axis[axis] = pad_size
|
||||
signal = F.pad(signal, pad_axis, "constant", pad_value)
|
||||
frames = signal.unfold(axis, frame_length, frame_step)
|
||||
return frames
|
||||
|
||||
|
||||
def program_to_slakh_program(program):
|
||||
# this is done very hackily, probably should use a custom mapping
|
||||
for slakh_program in sorted(SLAKH_CLASS_PROGRAMS.values(), reverse=True):
|
||||
if program >= slakh_program:
|
||||
return slakh_program
|
||||
|
||||
|
||||
def audio_to_frames(
|
||||
samples,
|
||||
hop_size: int,
|
||||
frame_rate: int,
|
||||
) -> Tuple[Sequence[Sequence[int]], torch.Tensor]:
|
||||
"""Convert audio samples to non-overlapping frames and frame times."""
|
||||
frame_size = hop_size
|
||||
samples = np.pad(samples, [0, frame_size - len(samples) % frame_size], mode="constant")
|
||||
|
||||
# Split audio into frames.
|
||||
frames = frame(
|
||||
torch.Tensor(samples).unsqueeze(0),
|
||||
frame_length=frame_size,
|
||||
frame_step=frame_size,
|
||||
pad_end=False, # TODO check why its off by 1 here when True
|
||||
)
|
||||
|
||||
num_frames = len(samples) // frame_size
|
||||
|
||||
times = np.arange(num_frames) / frame_rate
|
||||
return frames, times
|
||||
|
||||
|
||||
def note_sequence_to_onsets_and_offsets_and_programs(
|
||||
ns: note_seq.NoteSequence,
|
||||
) -> Tuple[Sequence[float], Sequence[NoteEventData]]:
|
||||
"""Extract onset & offset times and pitches & programs from a NoteSequence.
|
||||
|
||||
The onset & offset times will not necessarily be in sorted order.
|
||||
|
||||
Args:
|
||||
ns: NoteSequence from which to extract onsets and offsets.
|
||||
|
||||
Returns:
|
||||
times: A list of note onset and offset times. values: A list of NoteEventData objects where velocity is zero for
|
||||
note
|
||||
offsets.
|
||||
"""
|
||||
# Sort by program and pitch and put offsets before onsets as a tiebreaker for
|
||||
# subsequent stable sort.
|
||||
notes = sorted(ns.notes, key=lambda note: (note.is_drum, note.program, note.pitch))
|
||||
times = [note.end_time for note in notes if not note.is_drum] + [note.start_time for note in notes]
|
||||
values = [
|
||||
NoteEventData(pitch=note.pitch, velocity=0, program=note.program, is_drum=False)
|
||||
for note in notes
|
||||
if not note.is_drum
|
||||
] + [
|
||||
NoteEventData(pitch=note.pitch, velocity=note.velocity, program=note.program, is_drum=note.is_drum)
|
||||
for note in notes
|
||||
]
|
||||
return times, values
|
||||
|
||||
|
||||
def num_velocity_bins_from_codec(codec: Codec):
|
||||
"""Get number of velocity bins from event codec."""
|
||||
lo, hi = codec.event_type_range("velocity")
|
||||
return hi - lo
|
||||
|
||||
|
||||
# segment an array into segments of length n
|
||||
def segment(a, n):
|
||||
return [a[i : i + n] for i in range(0, len(a), n)]
|
||||
|
||||
|
||||
def velocity_to_bin(velocity, num_velocity_bins):
|
||||
if velocity == 0:
|
||||
return 0
|
||||
else:
|
||||
return math.ceil(num_velocity_bins * velocity / note_seq.MAX_MIDI_VELOCITY)
|
||||
|
||||
|
||||
def note_event_data_to_events(
|
||||
state: Optional[NoteEncodingState],
|
||||
value: NoteEventData,
|
||||
codec: Codec,
|
||||
) -> Sequence[Event]:
|
||||
"""Convert note event data to a sequence of events."""
|
||||
if value.velocity is None:
|
||||
# onsets only, no program or velocity
|
||||
return [Event("pitch", value.pitch)]
|
||||
else:
|
||||
num_velocity_bins = num_velocity_bins_from_codec(codec)
|
||||
velocity_bin = velocity_to_bin(value.velocity, num_velocity_bins)
|
||||
if value.program is None:
|
||||
# onsets + offsets + velocities only, no programs
|
||||
if state is not None:
|
||||
state.active_pitches[(value.pitch, 0)] = velocity_bin
|
||||
return [Event("velocity", velocity_bin), Event("pitch", value.pitch)]
|
||||
else:
|
||||
if value.is_drum:
|
||||
# drum events use a separate vocabulary
|
||||
return [Event("velocity", velocity_bin), Event("drum", value.pitch)]
|
||||
else:
|
||||
# program + velocity + pitch
|
||||
if state is not None:
|
||||
state.active_pitches[(value.pitch, value.program)] = velocity_bin
|
||||
return [
|
||||
Event("program", value.program),
|
||||
Event("velocity", velocity_bin),
|
||||
Event("pitch", value.pitch),
|
||||
]
|
||||
|
||||
|
||||
def note_encoding_state_to_events(state: NoteEncodingState) -> Sequence[Event]:
|
||||
"""Output program and pitch events for active notes plus a final tie event."""
|
||||
events = []
|
||||
for pitch, program in sorted(state.active_pitches.keys(), key=lambda k: k[::-1]):
|
||||
if state.active_pitches[(pitch, program)]:
|
||||
events += [Event("program", program), Event("pitch", pitch)]
|
||||
events.append(Event("tie", 0))
|
||||
return events
|
||||
|
||||
|
||||
def encode_and_index_events(
|
||||
state, event_times, event_values, codec, frame_times, encode_event_fn, encoding_state_to_events_fn=None
|
||||
):
|
||||
"""Encode a sequence of timed events and index to audio frame times.
|
||||
|
||||
Encodes time shifts as repeated single step shifts for later run length encoding.
|
||||
|
||||
Optionally, also encodes a sequence of "state events", keeping track of the current encoding state at each audio
|
||||
frame. This can be used e.g. to prepend events representing the current state to a targets segment.
|
||||
|
||||
Args:
|
||||
state: Initial event encoding state.
|
||||
event_times: Sequence of event times.
|
||||
event_values: Sequence of event values.
|
||||
encode_event_fn: Function that transforms event value into a sequence of one
|
||||
or more Event objects.
|
||||
codec: An Codec object that maps Event objects to indices.
|
||||
frame_times: Time for every audio frame.
|
||||
encoding_state_to_events_fn: Function that transforms encoding state into a
|
||||
sequence of one or more Event objects.
|
||||
|
||||
Returns:
|
||||
events: Encoded events and shifts. event_start_indices: Corresponding start event index for every audio frame.
|
||||
Note: one event can correspond to multiple audio indices due to sampling rate differences. This makes
|
||||
splitting sequences tricky because the same event can appear at the end of one sequence and the beginning of
|
||||
another.
|
||||
event_end_indices: Corresponding end event index for every audio frame. Used
|
||||
to ensure when slicing that one chunk ends where the next begins. Should always be true that
|
||||
event_end_indices[i] = event_start_indices[i + 1].
|
||||
state_events: Encoded "state" events representing the encoding state before
|
||||
each event.
|
||||
state_event_indices: Corresponding state event index for every audio frame.
|
||||
"""
|
||||
indices = np.argsort(event_times, kind="stable")
|
||||
event_steps = [round(event_times[i] * codec.steps_per_second) for i in indices]
|
||||
event_values = [event_values[i] for i in indices]
|
||||
|
||||
events = []
|
||||
state_events = []
|
||||
event_start_indices = []
|
||||
state_event_indices = []
|
||||
|
||||
cur_step = 0
|
||||
cur_event_idx = 0
|
||||
cur_state_event_idx = 0
|
||||
|
||||
def fill_event_start_indices_to_cur_step():
|
||||
while (
|
||||
len(event_start_indices) < len(frame_times)
|
||||
and frame_times[len(event_start_indices)] < cur_step / codec.steps_per_second
|
||||
):
|
||||
event_start_indices.append(cur_event_idx)
|
||||
state_event_indices.append(cur_state_event_idx)
|
||||
|
||||
for event_step, event_value in zip(event_steps, event_values):
|
||||
while event_step > cur_step:
|
||||
events.append(codec.encode_event(Event(type="shift", value=1)))
|
||||
cur_step += 1
|
||||
fill_event_start_indices_to_cur_step()
|
||||
cur_event_idx = len(events)
|
||||
cur_state_event_idx = len(state_events)
|
||||
if encoding_state_to_events_fn:
|
||||
# Dump state to state events *before* processing the next event, because
|
||||
# we want to capture the state prior to the occurrence of the event.
|
||||
for e in encoding_state_to_events_fn(state):
|
||||
state_events.append(codec.encode_event(e))
|
||||
|
||||
for e in encode_event_fn(state, event_value, codec):
|
||||
events.append(codec.encode_event(e))
|
||||
|
||||
# After the last event, continue filling out the event_start_indices array.
|
||||
# The inequality is not strict because if our current step lines up exactly
|
||||
# with (the start of) an audio frame, we need to add an additional shift event
|
||||
# to "cover" that frame.
|
||||
while cur_step / codec.steps_per_second <= frame_times[-1]:
|
||||
events.append(codec.encode_event(Event(type="shift", value=1)))
|
||||
cur_step += 1
|
||||
fill_event_start_indices_to_cur_step()
|
||||
cur_event_idx = len(events)
|
||||
|
||||
# Now fill in event_end_indices. We need this extra array to make sure that
|
||||
# when we slice events, each slice ends exactly where the subsequent slice
|
||||
# begins.
|
||||
event_end_indices = event_start_indices[1:] + [len(events)]
|
||||
|
||||
events = np.array(events).astype(np.int32)
|
||||
state_events = np.array(state_events).astype(np.int32)
|
||||
event_start_indices = segment(np.array(event_start_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
|
||||
event_end_indices = segment(np.array(event_end_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
|
||||
state_event_indices = segment(np.array(state_event_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
|
||||
|
||||
outputs = []
|
||||
for start_indices, end_indices, event_indices in zip(event_start_indices, event_end_indices, state_event_indices):
|
||||
outputs.append(
|
||||
{
|
||||
"inputs": events,
|
||||
"event_start_indices": start_indices,
|
||||
"event_end_indices": end_indices,
|
||||
"state_events": state_events,
|
||||
"state_event_indices": event_indices,
|
||||
}
|
||||
)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
def extract_sequence_with_indices(features, state_events_end_token=None, feature_key="inputs"):
|
||||
"""Extract target sequence corresponding to audio token segment."""
|
||||
features = features.copy()
|
||||
start_idx = features["event_start_indices"][0]
|
||||
end_idx = features["event_end_indices"][-1]
|
||||
|
||||
features[feature_key] = features[feature_key][start_idx:end_idx]
|
||||
|
||||
if state_events_end_token is not None:
|
||||
# Extract the state events corresponding to the audio start token, and
|
||||
# prepend them to the targets array.
|
||||
state_event_start_idx = features["state_event_indices"][0]
|
||||
state_event_end_idx = state_event_start_idx + 1
|
||||
while features["state_events"][state_event_end_idx - 1] != state_events_end_token:
|
||||
state_event_end_idx += 1
|
||||
features[feature_key] = np.concatenate(
|
||||
[
|
||||
features["state_events"][state_event_start_idx:state_event_end_idx],
|
||||
features[feature_key],
|
||||
],
|
||||
axis=0,
|
||||
)
|
||||
|
||||
return features
|
||||
|
||||
|
||||
def map_midi_programs(
|
||||
feature, codec: Codec, granularity_type: str = "full", feature_key: str = "inputs"
|
||||
) -> Mapping[str, Any]:
|
||||
"""Apply MIDI program map to token sequences."""
|
||||
granularity = PROGRAM_GRANULARITIES[granularity_type]
|
||||
|
||||
feature[feature_key] = granularity.tokens_map_fn(feature[feature_key], codec)
|
||||
return feature
|
||||
|
||||
|
||||
def run_length_encode_shifts_fn(
|
||||
features,
|
||||
codec: Codec,
|
||||
feature_key: str = "inputs",
|
||||
state_change_event_types: Sequence[str] = (),
|
||||
) -> Callable[[Mapping[str, Any]], Mapping[str, Any]]:
|
||||
"""Return a function that run-length encodes shifts for a given codec.
|
||||
|
||||
Args:
|
||||
codec: The Codec to use for shift events.
|
||||
feature_key: The feature key for which to run-length encode shifts.
|
||||
state_change_event_types: A list of event types that represent state
|
||||
changes; tokens corresponding to these event types will be interpreted as state changes and redundant ones
|
||||
will be removed.
|
||||
|
||||
Returns:
|
||||
A preprocessing function that run-length encodes single-step shifts.
|
||||
"""
|
||||
state_change_event_ranges = [codec.event_type_range(event_type) for event_type in state_change_event_types]
|
||||
|
||||
def run_length_encode_shifts(features: MutableMapping[str, Any]) -> Mapping[str, Any]:
|
||||
"""Combine leading/interior shifts, trim trailing shifts.
|
||||
|
||||
Args:
|
||||
features: Dict of features to process.
|
||||
|
||||
Returns:
|
||||
A dict of features.
|
||||
"""
|
||||
events = features[feature_key]
|
||||
|
||||
shift_steps = 0
|
||||
total_shift_steps = 0
|
||||
output = np.array([], dtype=np.int32)
|
||||
|
||||
current_state = np.zeros(len(state_change_event_ranges), dtype=np.int32)
|
||||
|
||||
for event in events:
|
||||
if codec.is_shift_event_index(event):
|
||||
shift_steps += 1
|
||||
total_shift_steps += 1
|
||||
|
||||
else:
|
||||
# If this event is a state change and has the same value as the current
|
||||
# state, we can skip it entirely.
|
||||
is_redundant = False
|
||||
for i, (min_index, max_index) in enumerate(state_change_event_ranges):
|
||||
if (min_index <= event) and (event <= max_index):
|
||||
if current_state[i] == event:
|
||||
is_redundant = True
|
||||
current_state[i] = event
|
||||
if is_redundant:
|
||||
continue
|
||||
|
||||
# Once we've reached a non-shift event, RLE all previous shift events
|
||||
# before outputting the non-shift event.
|
||||
if shift_steps > 0:
|
||||
shift_steps = total_shift_steps
|
||||
while shift_steps > 0:
|
||||
output_steps = np.minimum(codec.max_shift_steps, shift_steps)
|
||||
output = np.concatenate([output, [output_steps]], axis=0)
|
||||
shift_steps -= output_steps
|
||||
output = np.concatenate([output, [event]], axis=0)
|
||||
|
||||
features[feature_key] = output
|
||||
return features
|
||||
|
||||
return run_length_encode_shifts(features)
|
||||
|
||||
|
||||
def note_representation_processor_chain(features, codec: Codec, note_representation_config: NoteRepresentationConfig):
|
||||
tie_token = codec.encode_event(Event("tie", 0))
|
||||
state_events_end_token = tie_token if note_representation_config.include_ties else None
|
||||
|
||||
features = extract_sequence_with_indices(
|
||||
features, state_events_end_token=state_events_end_token, feature_key="inputs"
|
||||
)
|
||||
|
||||
features = map_midi_programs(features, codec)
|
||||
|
||||
features = run_length_encode_shifts_fn(features, codec, state_change_event_types=["velocity", "program"])
|
||||
|
||||
return features
|
||||
|
||||
|
||||
class MidiProcessor:
|
||||
def __init__(self):
|
||||
self.codec = Codec(
|
||||
max_shift_steps=DEFAULT_MAX_SHIFT_SECONDS * DEFAULT_STEPS_PER_SECOND,
|
||||
steps_per_second=DEFAULT_STEPS_PER_SECOND,
|
||||
event_ranges=[
|
||||
EventRange("pitch", note_seq.MIN_MIDI_PITCH, note_seq.MAX_MIDI_PITCH),
|
||||
EventRange("velocity", 0, DEFAULT_NUM_VELOCITY_BINS),
|
||||
EventRange("tie", 0, 0),
|
||||
EventRange("program", note_seq.MIN_MIDI_PROGRAM, note_seq.MAX_MIDI_PROGRAM),
|
||||
EventRange("drum", note_seq.MIN_MIDI_PITCH, note_seq.MAX_MIDI_PITCH),
|
||||
],
|
||||
)
|
||||
self.tokenizer = Tokenizer(self.codec.num_classes)
|
||||
self.note_representation_config = NoteRepresentationConfig(onsets_only=False, include_ties=True)
|
||||
|
||||
def __call__(self, midi: Union[bytes, os.PathLike, str]):
|
||||
if not isinstance(midi, bytes):
|
||||
with open(midi, "rb") as f:
|
||||
midi = f.read()
|
||||
|
||||
ns = note_seq.midi_to_note_sequence(midi)
|
||||
ns_sus = note_seq.apply_sustain_control_changes(ns)
|
||||
|
||||
for note in ns_sus.notes:
|
||||
if not note.is_drum:
|
||||
note.program = program_to_slakh_program(note.program)
|
||||
|
||||
samples = np.zeros(int(ns_sus.total_time * SAMPLE_RATE))
|
||||
|
||||
_, frame_times = audio_to_frames(samples, HOP_SIZE, FRAME_RATE)
|
||||
times, values = note_sequence_to_onsets_and_offsets_and_programs(ns_sus)
|
||||
|
||||
events = encode_and_index_events(
|
||||
state=NoteEncodingState(),
|
||||
event_times=times,
|
||||
event_values=values,
|
||||
frame_times=frame_times,
|
||||
codec=self.codec,
|
||||
encode_event_fn=note_event_data_to_events,
|
||||
encoding_state_to_events_fn=note_encoding_state_to_events,
|
||||
)
|
||||
|
||||
events = [
|
||||
note_representation_processor_chain(event, self.codec, self.note_representation_config) for event in events
|
||||
]
|
||||
input_tokens = [self.tokenizer.encode(event["inputs"]) for event in events]
|
||||
|
||||
return input_tokens
|
||||
|
|
@ -0,0 +1,86 @@
|
|||
# Copyright 2022 The Music Spectrogram Diffusion Authors.
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from transformers.modeling_utils import ModuleUtilsMixin
|
||||
from transformers.models.t5.modeling_t5 import T5Block, T5Config, T5LayerNorm
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramNotesEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
max_length: int,
|
||||
vocab_size: int,
|
||||
d_model: int,
|
||||
dropout_rate: float,
|
||||
num_layers: int,
|
||||
num_heads: int,
|
||||
d_kv: int,
|
||||
d_ff: int,
|
||||
feed_forward_proj: str,
|
||||
is_decoder: bool = False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.token_embedder = nn.Embedding(vocab_size, d_model)
|
||||
|
||||
self.position_encoding = nn.Embedding(max_length, d_model)
|
||||
self.position_encoding.weight.requires_grad = False
|
||||
|
||||
self.dropout_pre = nn.Dropout(p=dropout_rate)
|
||||
|
||||
t5config = T5Config(
|
||||
vocab_size=vocab_size,
|
||||
d_model=d_model,
|
||||
num_heads=num_heads,
|
||||
d_kv=d_kv,
|
||||
d_ff=d_ff,
|
||||
dropout_rate=dropout_rate,
|
||||
feed_forward_proj=feed_forward_proj,
|
||||
is_decoder=is_decoder,
|
||||
is_encoder_decoder=False,
|
||||
)
|
||||
|
||||
self.encoders = nn.ModuleList()
|
||||
for lyr_num in range(num_layers):
|
||||
lyr = T5Block(t5config)
|
||||
self.encoders.append(lyr)
|
||||
|
||||
self.layer_norm = T5LayerNorm(d_model)
|
||||
self.dropout_post = nn.Dropout(p=dropout_rate)
|
||||
|
||||
def forward(self, encoder_input_tokens, encoder_inputs_mask):
|
||||
x = self.token_embedder(encoder_input_tokens)
|
||||
|
||||
seq_length = encoder_input_tokens.shape[1]
|
||||
inputs_positions = torch.arange(seq_length, device=encoder_input_tokens.device)
|
||||
x += self.position_encoding(inputs_positions)
|
||||
|
||||
x = self.dropout_pre(x)
|
||||
|
||||
# inverted the attention mask
|
||||
input_shape = encoder_input_tokens.size()
|
||||
extended_attention_mask = self.get_extended_attention_mask(encoder_inputs_mask, input_shape)
|
||||
|
||||
for lyr in self.encoders:
|
||||
x = lyr(x, extended_attention_mask)[0]
|
||||
x = self.layer_norm(x)
|
||||
|
||||
return self.dropout_post(x), encoder_inputs_mask
|
||||
|
|
@ -0,0 +1,210 @@
|
|||
# Copyright 2022 The Music Spectrogram Diffusion Authors.
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import Any, Callable, List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ...models import T5FilmDecoder
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import is_onnx_available, logging, randn_tensor
|
||||
|
||||
|
||||
if is_onnx_available():
|
||||
from ..onnx_utils import OnnxRuntimeModel
|
||||
|
||||
from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
|
||||
from .continous_encoder import SpectrogramContEncoder
|
||||
from .notes_encoder import SpectrogramNotesEncoder
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
TARGET_FEATURE_LENGTH = 256
|
||||
|
||||
|
||||
class SpectrogramDiffusionPipeline(DiffusionPipeline):
|
||||
_optional_components = ["melgan"]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
notes_encoder: SpectrogramNotesEncoder,
|
||||
continuous_encoder: SpectrogramContEncoder,
|
||||
decoder: T5FilmDecoder,
|
||||
scheduler: DDPMScheduler,
|
||||
melgan: OnnxRuntimeModel if is_onnx_available() else Any,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
|
||||
# From MELGAN
|
||||
self.min_value = math.log(1e-5) # Matches MelGAN training.
|
||||
self.max_value = 4.0 # Largest value for most examples
|
||||
self.n_dims = 128
|
||||
|
||||
self.register_modules(
|
||||
notes_encoder=notes_encoder,
|
||||
continuous_encoder=continuous_encoder,
|
||||
decoder=decoder,
|
||||
scheduler=scheduler,
|
||||
melgan=melgan,
|
||||
)
|
||||
|
||||
def scale_features(self, features, output_range=(-1.0, 1.0), clip=False):
|
||||
"""Linearly scale features to network outputs range."""
|
||||
min_out, max_out = output_range
|
||||
if clip:
|
||||
features = torch.clip(features, self.min_value, self.max_value)
|
||||
# Scale to [0, 1].
|
||||
zero_one = (features - self.min_value) / (self.max_value - self.min_value)
|
||||
# Scale to [min_out, max_out].
|
||||
return zero_one * (max_out - min_out) + min_out
|
||||
|
||||
def scale_to_features(self, outputs, input_range=(-1.0, 1.0), clip=False):
|
||||
"""Invert by linearly scaling network outputs to features range."""
|
||||
min_out, max_out = input_range
|
||||
outputs = torch.clip(outputs, min_out, max_out) if clip else outputs
|
||||
# Scale to [0, 1].
|
||||
zero_one = (outputs - min_out) / (max_out - min_out)
|
||||
# Scale to [self.min_value, self.max_value].
|
||||
return zero_one * (self.max_value - self.min_value) + self.min_value
|
||||
|
||||
def encode(self, input_tokens, continuous_inputs, continuous_mask):
|
||||
tokens_mask = input_tokens > 0
|
||||
tokens_encoded, tokens_mask = self.notes_encoder(
|
||||
encoder_input_tokens=input_tokens, encoder_inputs_mask=tokens_mask
|
||||
)
|
||||
|
||||
continuous_encoded, continuous_mask = self.continuous_encoder(
|
||||
encoder_inputs=continuous_inputs, encoder_inputs_mask=continuous_mask
|
||||
)
|
||||
|
||||
return [(tokens_encoded, tokens_mask), (continuous_encoded, continuous_mask)]
|
||||
|
||||
def decode(self, encodings_and_masks, input_tokens, noise_time):
|
||||
timesteps = noise_time
|
||||
if not torch.is_tensor(timesteps):
|
||||
timesteps = torch.tensor([timesteps], dtype=torch.long, device=input_tokens.device)
|
||||
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(input_tokens.device)
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps * torch.ones(input_tokens.shape[0], dtype=timesteps.dtype, device=timesteps.device)
|
||||
|
||||
logits = self.decoder(
|
||||
encodings_and_masks=encodings_and_masks, decoder_input_tokens=input_tokens, decoder_noise_time=timesteps
|
||||
)
|
||||
return logits
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
input_tokens: List[List[int]],
|
||||
generator: Optional[torch.Generator] = None,
|
||||
num_inference_steps: int = 100,
|
||||
return_dict: bool = True,
|
||||
output_type: str = "numpy",
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
) -> Union[AudioPipelineOutput, Tuple]:
|
||||
if (callback_steps is None) or (
|
||||
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
||||
):
|
||||
raise ValueError(
|
||||
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
|
||||
f" {type(callback_steps)}."
|
||||
)
|
||||
|
||||
pred_mel = np.zeros([1, TARGET_FEATURE_LENGTH, self.n_dims], dtype=np.float32)
|
||||
full_pred_mel = np.zeros([1, 0, self.n_dims], np.float32)
|
||||
ones = torch.ones((1, TARGET_FEATURE_LENGTH), dtype=bool, device=self.device)
|
||||
|
||||
for i, encoder_input_tokens in enumerate(input_tokens):
|
||||
if i == 0:
|
||||
encoder_continuous_inputs = torch.from_numpy(pred_mel[:1].copy()).to(
|
||||
device=self.device, dtype=self.decoder.dtype
|
||||
)
|
||||
# The first chunk has no previous context.
|
||||
encoder_continuous_mask = torch.zeros((1, TARGET_FEATURE_LENGTH), dtype=bool, device=self.device)
|
||||
else:
|
||||
# The full song pipeline does not feed in a context feature, so the mask
|
||||
# will be all 0s after the feature converter. Because we know we're
|
||||
# feeding in a full context chunk from the previous prediction, set it
|
||||
# to all 1s.
|
||||
encoder_continuous_mask = ones
|
||||
|
||||
encoder_continuous_inputs = self.scale_features(
|
||||
encoder_continuous_inputs, output_range=[-1.0, 1.0], clip=True
|
||||
)
|
||||
|
||||
encodings_and_masks = self.encode(
|
||||
input_tokens=torch.IntTensor([encoder_input_tokens]).to(device=self.device),
|
||||
continuous_inputs=encoder_continuous_inputs,
|
||||
continuous_mask=encoder_continuous_mask,
|
||||
)
|
||||
|
||||
# Sample encoder_continuous_inputs shaped gaussian noise to begin loop
|
||||
x = randn_tensor(
|
||||
shape=encoder_continuous_inputs.shape,
|
||||
generator=generator,
|
||||
device=self.device,
|
||||
dtype=self.decoder.dtype,
|
||||
)
|
||||
|
||||
# set step values
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
# Denoising diffusion loop
|
||||
for j, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
|
||||
output = self.decode(
|
||||
encodings_and_masks=encodings_and_masks,
|
||||
input_tokens=x,
|
||||
noise_time=t / self.scheduler.config.num_train_timesteps, # rescale to [0, 1)
|
||||
)
|
||||
|
||||
# Compute previous output: x_t -> x_t-1
|
||||
x = self.scheduler.step(output, t, x, generator=generator).prev_sample
|
||||
|
||||
mel = self.scale_to_features(x, input_range=[-1.0, 1.0])
|
||||
encoder_continuous_inputs = mel[:1]
|
||||
pred_mel = mel.cpu().float().numpy()
|
||||
|
||||
full_pred_mel = np.concatenate([full_pred_mel, pred_mel[:1]], axis=1)
|
||||
|
||||
# call the callback, if provided
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, full_pred_mel)
|
||||
|
||||
logger.info("Generated segment", i)
|
||||
|
||||
if output_type == "numpy" and not is_onnx_available():
|
||||
raise ValueError(
|
||||
"Cannot return output in 'np' format if ONNX is not available. Make sure to have ONNX installed or set 'output_type' to 'mel'."
|
||||
)
|
||||
elif output_type == "numpy" and self.melgan is None:
|
||||
raise ValueError(
|
||||
"Cannot return output in 'np' format if melgan component is not defined. Make sure to define `self.melgan` or set 'output_type' to 'mel'."
|
||||
)
|
||||
|
||||
if output_type == "numpy":
|
||||
output = self.melgan(input_features=full_pred_mel.astype(np.float32))
|
||||
else:
|
||||
output = full_pred_mel
|
||||
|
||||
if not return_dict:
|
||||
return (output,)
|
||||
|
||||
return AudioPipelineOutput(audios=output)
|
||||
|
|
@ -55,6 +55,7 @@ from .import_utils import (
|
|||
is_k_diffusion_available,
|
||||
is_k_diffusion_version,
|
||||
is_librosa_available,
|
||||
is_note_seq_available,
|
||||
is_omegaconf_available,
|
||||
is_onnx_available,
|
||||
is_safetensors_available,
|
||||
|
|
|
|||
|
|
@ -0,0 +1,17 @@
|
|||
# This file is autogenerated by the command `make fix-copies`, do not edit.
|
||||
from ..utils import DummyObject, requires_backends
|
||||
|
||||
|
||||
class MidiProcessor(metaclass=DummyObject):
|
||||
_backends = ["note_seq"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["note_seq"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["note_seq"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["note_seq"])
|
||||
|
|
@ -62,6 +62,21 @@ class PriorTransformer(metaclass=DummyObject):
|
|||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class T5FilmDecoder(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class Transformer2DModel(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,17 @@
|
|||
# This file is autogenerated by the command `make fix-copies`, do not edit.
|
||||
from ..utils import DummyObject, requires_backends
|
||||
|
||||
|
||||
class SpectrogramDiffusionPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "note_seq"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "note_seq"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "note_seq"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "note_seq"])
|
||||
|
|
@ -218,6 +218,13 @@ try:
|
|||
except importlib_metadata.PackageNotFoundError:
|
||||
_k_diffusion_available = False
|
||||
|
||||
_note_seq_available = importlib.util.find_spec("note_seq") is not None
|
||||
try:
|
||||
_note_seq_version = importlib_metadata.version("note_seq")
|
||||
logger.debug(f"Successfully imported note-seq version {_note_seq_version}")
|
||||
except importlib_metadata.PackageNotFoundError:
|
||||
_note_seq_available = False
|
||||
|
||||
_wandb_available = importlib.util.find_spec("wandb") is not None
|
||||
try:
|
||||
_wandb_version = importlib_metadata.version("wandb")
|
||||
|
|
@ -304,6 +311,10 @@ def is_k_diffusion_available():
|
|||
return _k_diffusion_available
|
||||
|
||||
|
||||
def is_note_seq_available():
|
||||
return _note_seq_available
|
||||
|
||||
|
||||
def is_wandb_available():
|
||||
return _wandb_available
|
||||
|
||||
|
|
@ -380,6 +391,12 @@ K_DIFFUSION_IMPORT_ERROR = """
|
|||
install k-diffusion`
|
||||
"""
|
||||
|
||||
# docstyle-ignore
|
||||
NOTE_SEQ_IMPORT_ERROR = """
|
||||
{0} requires the note-seq library but it was not found in your environment. You can install it with pip: `pip
|
||||
install note-seq`
|
||||
"""
|
||||
|
||||
# docstyle-ignore
|
||||
WANDB_IMPORT_ERROR = """
|
||||
{0} requires the wandb library but it was not found in your environment. You can install it with pip: `pip
|
||||
|
|
@ -416,6 +433,7 @@ BACKENDS_MAPPING = OrderedDict(
|
|||
("unidecode", (is_unidecode_available, UNIDECODE_IMPORT_ERROR)),
|
||||
("librosa", (is_librosa_available, LIBROSA_IMPORT_ERROR)),
|
||||
("k_diffusion", (is_k_diffusion_available, K_DIFFUSION_IMPORT_ERROR)),
|
||||
("note_seq", (is_note_seq_available, NOTE_SEQ_IMPORT_ERROR)),
|
||||
("wandb", (is_wandb_available, WANDB_IMPORT_ERROR)),
|
||||
("omegaconf", (is_omegaconf_available, OMEGACONF_IMPORT_ERROR)),
|
||||
("tensorboard", (_tensorboard_available, TENSORBOARD_IMPORT_ERROR)),
|
||||
|
|
|
|||
|
|
@ -21,6 +21,7 @@ from .import_utils import (
|
|||
BACKENDS_MAPPING,
|
||||
is_compel_available,
|
||||
is_flax_available,
|
||||
is_note_seq_available,
|
||||
is_onnx_available,
|
||||
is_opencv_available,
|
||||
is_torch_available,
|
||||
|
|
@ -198,6 +199,13 @@ def require_onnxruntime(test_case):
|
|||
return unittest.skipUnless(is_onnx_available(), "test requires onnxruntime")(test_case)
|
||||
|
||||
|
||||
def require_note_seq(test_case):
|
||||
"""
|
||||
Decorator marking a test that requires note_seq. These tests are skipped when note_seq isn't installed.
|
||||
"""
|
||||
return unittest.skipUnless(is_note_seq_available(), "test requires note_seq")(test_case)
|
||||
|
||||
|
||||
def load_numpy(arry: Union[str, np.ndarray], local_path: Optional[str] = None) -> np.ndarray:
|
||||
if isinstance(arry, str):
|
||||
# local_path = "/home/patrick_huggingface_co/"
|
||||
|
|
|
|||
Binary file not shown.
|
|
@ -102,3 +102,7 @@ UNCONDITIONAL_IMAGE_GENERATION_BATCH_PARAMS = frozenset([])
|
|||
UNCONDITIONAL_AUDIO_GENERATION_PARAMS = frozenset(["batch_size"])
|
||||
|
||||
UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS = frozenset([])
|
||||
|
||||
TOKENS_TO_AUDIO_GENERATION_PARAMS = frozenset(["input_tokens"])
|
||||
|
||||
TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS = frozenset(["input_tokens"])
|
||||
|
|
|
|||
|
|
@ -0,0 +1,231 @@
|
|||
# coding=utf-8
|
||||
# Copyright 2022 HuggingFace Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import gc
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from diffusers import DDPMScheduler, MidiProcessor, SpectrogramDiffusionPipeline
|
||||
from diffusers.pipelines.spectrogram_diffusion import SpectrogramContEncoder, SpectrogramNotesEncoder, T5FilmDecoder
|
||||
from diffusers.utils import require_torch_gpu, skip_mps, slow, torch_device
|
||||
from diffusers.utils.testing_utils import require_note_seq, require_onnxruntime
|
||||
|
||||
from ...pipeline_params import TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS, TOKENS_TO_AUDIO_GENERATION_PARAMS
|
||||
from ...test_pipelines_common import PipelineTesterMixin
|
||||
|
||||
|
||||
torch.backends.cuda.matmul.allow_tf32 = False
|
||||
|
||||
|
||||
MIDI_FILE = "./tests/fixtures/elise_format0.mid"
|
||||
|
||||
|
||||
class SpectrogramDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
pipeline_class = SpectrogramDiffusionPipeline
|
||||
required_optional_params = PipelineTesterMixin.required_optional_params - {
|
||||
"callback",
|
||||
"latents",
|
||||
"callback_steps",
|
||||
"output_type",
|
||||
"num_images_per_prompt",
|
||||
}
|
||||
test_attention_slicing = False
|
||||
test_cpu_offload = False
|
||||
batch_params = TOKENS_TO_AUDIO_GENERATION_PARAMS
|
||||
params = TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS
|
||||
|
||||
def get_dummy_components(self):
|
||||
torch.manual_seed(0)
|
||||
notes_encoder = SpectrogramNotesEncoder(
|
||||
max_length=2048,
|
||||
vocab_size=1536,
|
||||
d_model=768,
|
||||
dropout_rate=0.1,
|
||||
num_layers=1,
|
||||
num_heads=1,
|
||||
d_kv=4,
|
||||
d_ff=2048,
|
||||
feed_forward_proj="gated-gelu",
|
||||
)
|
||||
|
||||
continuous_encoder = SpectrogramContEncoder(
|
||||
input_dims=128,
|
||||
targets_context_length=256,
|
||||
d_model=768,
|
||||
dropout_rate=0.1,
|
||||
num_layers=1,
|
||||
num_heads=1,
|
||||
d_kv=4,
|
||||
d_ff=2048,
|
||||
feed_forward_proj="gated-gelu",
|
||||
)
|
||||
|
||||
decoder = T5FilmDecoder(
|
||||
input_dims=128,
|
||||
targets_length=256,
|
||||
max_decoder_noise_time=20000.0,
|
||||
d_model=768,
|
||||
num_layers=1,
|
||||
num_heads=1,
|
||||
d_kv=4,
|
||||
d_ff=2048,
|
||||
dropout_rate=0.1,
|
||||
)
|
||||
|
||||
scheduler = DDPMScheduler()
|
||||
|
||||
components = {
|
||||
"notes_encoder": notes_encoder.eval(),
|
||||
"continuous_encoder": continuous_encoder.eval(),
|
||||
"decoder": decoder.eval(),
|
||||
"scheduler": scheduler,
|
||||
"melgan": None,
|
||||
}
|
||||
return components
|
||||
|
||||
def get_dummy_inputs(self, device, seed=0):
|
||||
if str(device).startswith("mps"):
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = torch.Generator(device=device).manual_seed(seed)
|
||||
inputs = {
|
||||
"input_tokens": [
|
||||
[1134, 90, 1135, 1133, 1080, 112, 1132, 1080, 1133, 1079, 133, 1132, 1079, 1133, 1] + [0] * 2033
|
||||
],
|
||||
"generator": generator,
|
||||
"num_inference_steps": 4,
|
||||
"output_type": "mel",
|
||||
}
|
||||
return inputs
|
||||
|
||||
def test_spectrogram_diffusion(self):
|
||||
device = "cpu" # ensure determinism for the device-dependent torch.Generator
|
||||
components = self.get_dummy_components()
|
||||
pipe = SpectrogramDiffusionPipeline(**components)
|
||||
pipe = pipe.to(device)
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
inputs = self.get_dummy_inputs(device)
|
||||
output = pipe(**inputs)
|
||||
mel = output.audios
|
||||
|
||||
mel_slice = mel[0, -3:, -3:]
|
||||
|
||||
assert mel_slice.shape == (3, 3)
|
||||
expected_slice = np.array(
|
||||
[-11.512925, -4.788215, -0.46172905, -2.051715, -10.539147, -10.970963, -9.091634, 4.0, 4.0]
|
||||
)
|
||||
assert np.abs(mel_slice.flatten() - expected_slice).max() < 1e-2
|
||||
|
||||
@skip_mps
|
||||
def test_save_load_local(self):
|
||||
return super().test_save_load_local()
|
||||
|
||||
@skip_mps
|
||||
def test_dict_tuple_outputs_equivalent(self):
|
||||
return super().test_dict_tuple_outputs_equivalent()
|
||||
|
||||
@skip_mps
|
||||
def test_save_load_optional_components(self):
|
||||
return super().test_save_load_optional_components()
|
||||
|
||||
@skip_mps
|
||||
def test_attention_slicing_forward_pass(self):
|
||||
return super().test_attention_slicing_forward_pass()
|
||||
|
||||
def test_inference_batch_single_identical(self):
|
||||
pass
|
||||
|
||||
def test_inference_batch_consistent(self):
|
||||
pass
|
||||
|
||||
|
||||
@slow
|
||||
@require_torch_gpu
|
||||
@require_onnxruntime
|
||||
@require_note_seq
|
||||
class PipelineIntegrationTests(unittest.TestCase):
|
||||
def tearDown(self):
|
||||
# clean up the VRAM after each test
|
||||
super().tearDown()
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
def test_callback(self):
|
||||
# TODO - test that pipeline can decode tokens in a callback
|
||||
# so that music can be played live
|
||||
device = torch_device
|
||||
|
||||
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
|
||||
melgan = pipe.melgan
|
||||
pipe.melgan = None
|
||||
|
||||
pipe = pipe.to(device)
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
def callback(step, mel_output):
|
||||
# decode mel to audio
|
||||
audio = melgan(input_features=mel_output.astype(np.float32))[0]
|
||||
assert len(audio[0]) == 81920 * (step + 1)
|
||||
# simulate that audio is played
|
||||
return audio
|
||||
|
||||
processor = MidiProcessor()
|
||||
input_tokens = processor(MIDI_FILE)
|
||||
|
||||
input_tokens = input_tokens[:3]
|
||||
generator = torch.manual_seed(0)
|
||||
pipe(input_tokens, num_inference_steps=5, generator=generator, callback=callback, output_type="mel")
|
||||
|
||||
def test_spectrogram_fast(self):
|
||||
device = torch_device
|
||||
|
||||
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
|
||||
pipe = pipe.to(device)
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
processor = MidiProcessor()
|
||||
|
||||
input_tokens = processor(MIDI_FILE)
|
||||
# just run two denoising loops
|
||||
input_tokens = input_tokens[:2]
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
output = pipe(input_tokens, num_inference_steps=2, generator=generator)
|
||||
|
||||
audio = output.audios[0]
|
||||
|
||||
assert abs(np.abs(audio).sum() - 3612.841) < 1e-1
|
||||
|
||||
def test_spectrogram(self):
|
||||
device = torch_device
|
||||
|
||||
pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
|
||||
pipe = pipe.to(device)
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
|
||||
processor = MidiProcessor()
|
||||
|
||||
input_tokens = processor(MIDI_FILE)
|
||||
|
||||
# just run 4 denoising loops
|
||||
input_tokens = input_tokens[:4]
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
output = pipe(input_tokens, num_inference_steps=100, generator=generator)
|
||||
|
||||
audio = output.audios[0]
|
||||
assert abs(np.abs(audio).sum() - 9389.1111) < 5e-2
|
||||
Loading…
Reference in New Issue