diff --git a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
index b5fa350e..aafbf5b0 100644
--- a/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
+++ b/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -135,6 +135,113 @@ This should take only around 3-4 seconds on GPU (depending on hardware). The out
+## Combining multiple conditionings
+
+Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
+
+When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
+
+It can also be helpful to vary the `controlnet_conditioning_scales` to emphasize one conditioning over the other.
+
+### Canny conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+ +
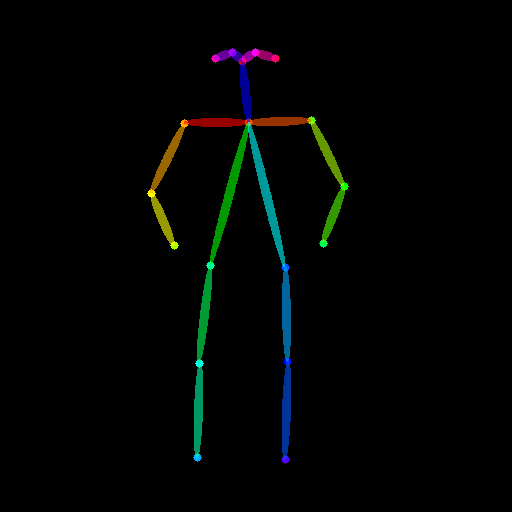
+### Openpose conditioning
+
+The original image:
+
+
+
+### Openpose conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+ +
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+
+
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+ +
## Available checkpoints
ControlNet requires a *control image* in addition to the text-to-image *prompt*.
+
## Available checkpoints
ControlNet requires a *control image* in addition to the text-to-image *prompt*.