|
|
||
|---|---|---|
| examples | ||
| src/diffusers | ||
| tests | ||
| utils | ||
| .gitignore | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| pyproject.toml | ||
| setup.cfg | ||
| setup.py | ||
README.md
Diffusers
Definitions
Models: Single neural network that models p_θ(x_t-1|x_t) and is trained to “denoise” to image Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
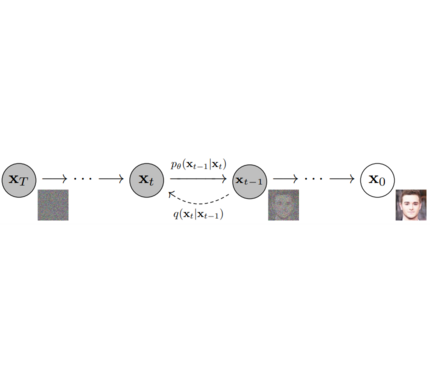
Schedulers: Algorithm to compute previous image according to alpha, beta schedule and to sample noise. Should be used for both training and inference. Example: Gaussian DDPM, DDIM, PMLS, DEIN


Diffusion Pipeline: End-to-end pipeline that includes multiple diffusion models, possible text encoders, CLIP Example: GLIDE,CompVis/Latent-Diffusion, Imagen, DALL-E
Quickstart
git clone https://github.com/huggingface/diffusers.git
cd diffusers && pip install -e .
1. diffusers as a central modular diffusion and sampler library
diffusers is more modularized than transformers. The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
Both models and schedulers should be load- and saveable from the Hub.
Example for DDPM:
import torch
from diffusers import UNetModel, DDPMScheduler
import PIL
import numpy as np
import tqdm
generator = torch.manual_seed(0)
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
# 1. Load models
noise_scheduler = DDPMScheduler.from_config("fusing/ddpm-lsun-church", tensor_format="pt")
unet = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
# 2. Sample gaussian noise
image = torch.randn(
(1, unet.in_channels, unet.resolution, unet.resolution),
generator=generator,
)
image = image.to(torch_device)
# 3. Denoise
num_prediction_steps = len(noise_scheduler)
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
# predict noise residual
with torch.no_grad():
residual = unet(image, t)
# predict previous mean of image x_t-1
pred_prev_image = noise_scheduler.step(residual, image, t)
# optionally sample variance
variance = 0
if t > 0:
noise = torch.randn(image.shape, generator=generator).to(image.device)
variance = noise_scheduler.get_variance(t).sqrt() * noise
# set current image to prev_image: x_t -> x_t-1
image = pred_prev_image + variance
# 5. process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# 6. save image
image_pil.save("test.png")
Example for DDIM:
import torch
from diffusers import UNetModel, DDIMScheduler
import PIL
import numpy as np
import tqdm
generator = torch.manual_seed(0)
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
# 1. Load models
noise_scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
unet = UNetModel.from_pretrained("fusing/ddpm-celeba-hq").to(torch_device)
# 2. Sample gaussian noise
image = torch.randn(
(1, unet.in_channels, unet.resolution, unet.resolution),
generator=generator,
)
image = image.to(torch_device)
# 3. Denoise
num_inference_steps = 50
eta = 0.0 # <- deterministic sampling
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
# 1. predict noise residual
orig_t = noise_scheduler.get_orig_t(t, num_inference_steps)
with torch.no_grad():
residual = unet(image, orig_t)
# 2. predict previous mean of image x_t-1
pred_prev_image = noise_scheduler.step(residual, image, t, num_inference_steps, eta)
# 3. optionally sample variance
variance = 0
if eta > 0:
noise = torch.randn(image.shape, generator=generator).to(image.device)
variance = noise_scheduler.get_variance(t).sqrt() * eta * noise
# 4. set current image to prev_image: x_t -> x_t-1
image = pred_prev_image + variance
# 5. process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# 6. save image
image_pil.save("test.png")
2. diffusers as a collection of most important Diffusion systems (GLIDE, Dalle, ...)
models directory in repository hosts the complete code necessary for running a diffusion system as well as to train it. A DiffusionPipeline class allows to easily run the diffusion model in inference:
Example image generation with DDPM
from diffusers import DiffusionPipeline
import PIL.Image
import numpy as np
# load model and scheduler
ddpm = DiffusionPipeline.from_pretrained("fusing/ddpm-lsun-bedroom")
# run pipeline in inference (sample random noise and denoise)
image = ddpm()
# process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
Text to Image generation with Latent Diffusion
Note: To use latent diffusion install transformers from this branch.
from diffusers import DiffusionPipeline
ldm = DiffusionPipeline.from_pretrained("fusing/latent-diffusion-text2im-large")
generator = torch.manual_seed(42)
prompt = "A painting of a squirrel eating a burger"
image = ldm([prompt], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50)
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = image_processed * 255.
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
Text to speech with BDDM
Follow the isnstructions here to load tacotron2 model.
import torch
from diffusers import BDDM, DiffusionPipeline
torch_device = "cuda"
# load the BDDM pipeline
bddm = DiffusionPipeline.from_pretrained("fusing/diffwave-vocoder-ljspeech")
# load tacotron2 to get the mel spectograms
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')
tacotron2 = tacotron2.to(torch_device).eval()
text = "Hello world, I missed you so much."
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
sequences, lengths = utils.prepare_input_sequence([text])
# generate mel spectograms using text
with torch.no_grad():
mel_spec, _, _ = tacotron2.infer(sequences, lengths)
# generate the speech by passing mel spectograms to BDDM pipeline
generator = torch.manual_seed(0)
audio = bddm(mel_spec, generator, torch_device)
# save generated audio
from scipy.io.wavfile import write as wavwrite
sampling_rate = 22050
wavwrite("generated_audio.wav", sampling_rate, audio.squeeze().cpu().numpy())
Library structure:
├── LICENSE
├── Makefile
├── README.md
├── pyproject.toml
├── setup.cfg
├── setup.py
├── src
│ ├── diffusers
│ ├── __init__.py
│ ├── configuration_utils.py
│ ├── dependency_versions_check.py
│ ├── dependency_versions_table.py
│ ├── dynamic_modules_utils.py
│ ├── modeling_utils.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── unet.py
│ │ ├── unet_glide.py
│ │ └── unet_ldm.py
│ ├── pipeline_utils.py
│ ├── pipelines
│ │ ├── __init__.py
│ │ ├── configuration_ldmbert.py
│ │ ├── conversion_glide.py
│ │ ├── modeling_vae.py
│ │ ├── pipeline_bddm.py
│ │ ├── pipeline_ddim.py
│ │ ├── pipeline_ddpm.py
│ │ ├── pipeline_glide.py
│ │ └── pipeline_latent_diffusion.py
│ ├── schedulers
│ │ ├── __init__.py
│ │ ├── classifier_free_guidance.py
│ │ ├── scheduling_ddim.py
│ │ ├── scheduling_ddpm.py
│ │ ├── scheduling_plms.py
│ │ └── scheduling_utils.py
│ ├── testing_utils.py
│ └── utils
│ ├── __init__.py
│ └── logging.py
├── tests
│ ├── __init__.py
│ ├── test_modeling_utils.py
│ └── test_scheduler.py
└── utils
├── check_config_docstrings.py
├── check_copies.py
├── check_dummies.py
├── check_inits.py
├── check_repo.py
├── check_table.py
└── check_tf_ops.py