With this option, it is possible to require a linear commit history with
the following benefits over the next best option `Rebase+fast-forward`:
The original commits continue existing, with the original signatures
continuing to stay valid instead of being rewritten, there is no merge
commit, and reverting commits becomes easier.
Closes#24906
## Purpose
This is a refactor toward building an abstraction over managing git
repositories.
Afterwards, it does not matter anymore if they are stored on the local
disk or somewhere remote.
## What this PR changes
We used `git.OpenRepository` everywhere previously.
Now, we should split them into two distinct functions:
Firstly, there are temporary repositories which do not change:
```go
git.OpenRepository(ctx, diskPath)
```
Gitea managed repositories having a record in the database in the
`repository` table are moved into the new package `gitrepo`:
```go
gitrepo.OpenRepository(ctx, repo_model.Repo)
```
Why is `repo_model.Repository` the second parameter instead of file
path?
Because then we can easily adapt our repository storage strategy.
The repositories can be stored locally, however, they could just as well
be stored on a remote server.
## Further changes in other PRs
- A Git Command wrapper on package `gitrepo` could be created. i.e.
`NewCommand(ctx, repo_model.Repository, commands...)`. `git.RunOpts{Dir:
repo.RepoPath()}`, the directory should be empty before invoking this
method and it can be filled in the function only. #28940
- Remove the `RepoPath()`/`WikiPath()` functions to reduce the
possibility of mistakes.
---------
Co-authored-by: delvh <dev.lh@web.de>
Sometimes you need to work on a feature which depends on another (unmerged) feature.
In this case, you may create a PR based on that feature instead of the main branch.
Currently, such PRs will be closed without the possibility to reopen in case the parent feature is merged and its branch is deleted.
Automatic target branch change make life a lot easier in such cases.
Github and Bitbucket behave in such way.
Example:
$PR_1$: main <- feature1
$PR_2$: feature1 <- feature2
Currently, merging $PR_1$ and deleting its branch leads to $PR_2$ being closed without the possibility to reopen.
This is both annoying and loses the review history when you open a new PR.
With this change, $PR_2$ will change its target branch to main ($PR_2$: main <- feature2) after $PR_1$ has been merged and its branch has been deleted.
This behavior is enabled by default but can be disabled.
For security reasons, this target branch change will not be executed when merging PRs targeting another repo.
Fixes#27062Fixes#18408
---------
Co-authored-by: Denys Konovalov <kontakt@denyskon.de>
Co-authored-by: delvh <dev.lh@web.de>
- If there's a error with the Git command in `checkIfPRContentChanged`
the stderr wasn't concatendated to the error, which results in still not
knowing why an error happend.
- Adds concatenation for stderr to the returned error.
- Ref: https://codeberg.org/forgejo/forgejo/issues/2077
Co-authored-by: Gusted <postmaster@gusted.xyz>
The 4 functions are duplicated, especially as interface methods. I think
we just need to keep `MustID` the only one and remove other 3.
```
MustID(b []byte) ObjectID
MustIDFromString(s string) ObjectID
NewID(b []byte) (ObjectID, error)
NewIDFromString(s string) (ObjectID, error)
```
Introduced the new interfrace method `ComputeHash` which will replace
the interface `HasherInterface`. Now we don't need to keep two
interfaces.
Reintroduced `git.NewIDFromString` and `git.MustIDFromString`. The new
function will detect the hash length to decide which objectformat of it.
If it's 40, then it's SHA1. If it's 64, then it's SHA256. This will be
right if the commitID is a full one. So the parameter should be always a
full commit id.
@AdamMajer Please review.
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
assert.Fail() will continue to execute the code while assert.FailNow()
not. I thought those uses of assert.Fail() should exit immediately.
PS: perhaps it's a good idea to use
[require](https://pkg.go.dev/github.com/stretchr/testify/require)
somewhere because the assert package's default behavior does not exit
when an error occurs, which makes it difficult to find the root error
reason.
This pull request is a minor code cleanup.
From the Go specification (https://go.dev/ref/spec#For_range):
> "1. For a nil slice, the number of iterations is 0."
> "3. If the map is nil, the number of iterations is 0."
`len` returns 0 if the slice or map is nil
(https://pkg.go.dev/builtin#len). Therefore, checking `len(v) > 0`
before a loop is unnecessary.
---
At the time of writing this pull request, there wasn't a lint rule that
catches these issues. The closest I could find is
https://staticcheck.dev/docs/checks/#S103
Signed-off-by: Eng Zer Jun <engzerjun@gmail.com>
Part of #27065
This PR touches functions used in templates. As templates are not static
typed, errors are harder to find, but I hope I catch it all. I think
some tests from other persons do not hurt.
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Fix#26129
Replace #26258
This PR will introduce a transaction on creating pull request so that if
some step failed, it will rollback totally. And there will be no dirty
pull request exist.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
I noticed that `issue_service.CreateComment` adds transaction operations
on `issues_model.CreateComment`, we can merge the two functions and we
can avoid calling each other's methods in the `services` layer.
Co-authored-by: Giteabot <teabot@gitea.io>
In the original implementation, we can only get the first 30 records of
the commit status (the default paging size), if the commit status is
more than 30, it will lead to the bug #25990. I made the following two
changes.
- On the page, use the ` db.ListOptions{ListAll: true}` parameter
instead of `db.ListOptions{}`
- The `GetLatestCommitStatus` function makes a determination as to
whether or not a pager is being used.
fixed#25990
To avoid deadlock problem, almost database related functions should be
have ctx as the first parameter.
This PR do a refactor for some of these functions.
Related #14180
Related #25233
Related #22639Close#19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Before there was a "graceful function": RunWithShutdownFns, it's mainly
for some modules which doesn't support context.
The old queue system doesn't work well with context, so the old queues
need it.
After the queue refactoring, the new queue works with context well, so,
use Golang context as much as possible, the `RunWithShutdownFns` could
be removed (replaced by RunWithCancel for context cancel mechanism), the
related code could be simplified.
This PR also fixes some legacy queue-init problems, eg:
* typo : archiver: "unable to create codes indexer queue" => "unable to
create repo-archive queue"
* no nil check for failed queues, which causes unfriendly panic
After this PR, many goroutines could have better display name:


Use `default_merge_message/REBASE_TEMPLATE.md` for amending the message
of the last commit in the list of commits that was merged. Previously
this template was mentioned in the documentation but not actually used.
In this template additional variables `CommitTitle` and `CommitBody` are
available, for the title and body of the commit.
Ideally the message of every commit would be updated using the template,
but doing an interactive rebase or merging commits one by one is
complicated, so that is left as a future improvement.
This PR is to allow users to specify status checks by patterns. Users
can enter patterns in the "Status Check Pattern" `textarea` to match
status checks and each line specifies a pattern. If "Status Check" is
enabled, patterns cannot be empty and user must enter at least one
pattern.
Users will no longer be able to choose status checks from the table. But
a __*`Matched`*__ mark will be added to the matched checks to help users
enter patterns.
Benefits:
- Even if no status checks have been completed, users can specify
necessary status checks in advance.
- More flexible. Users can specify a series of status checks by one
pattern.
Before:
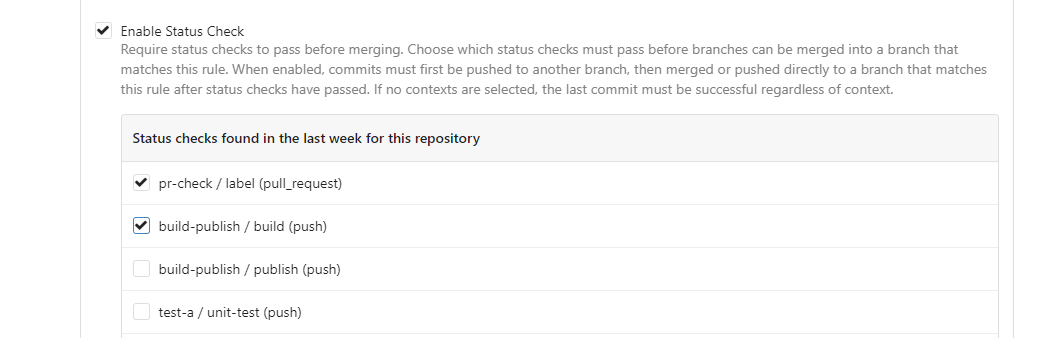
After:

---------
Co-authored-by: silverwind <me@silverwind.io>
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Close#24213
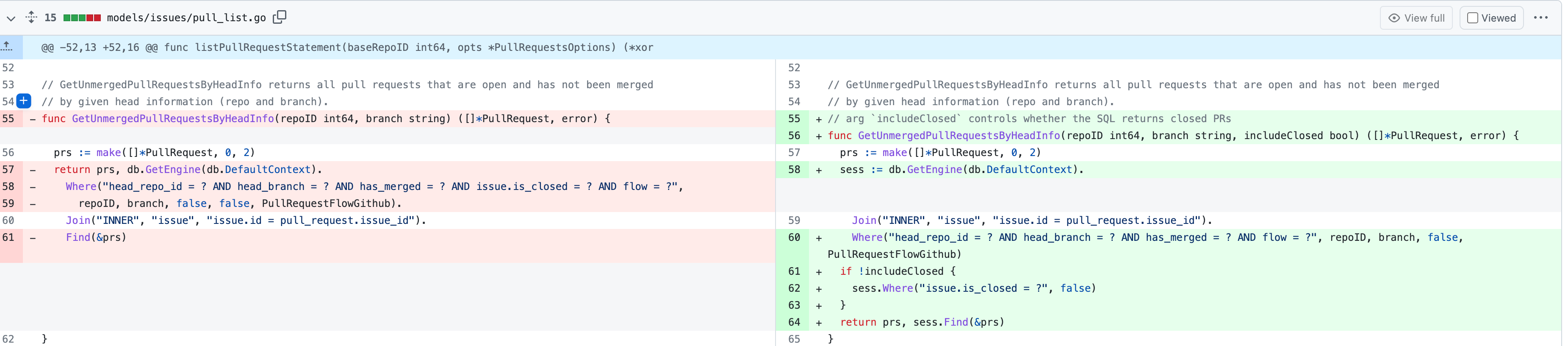
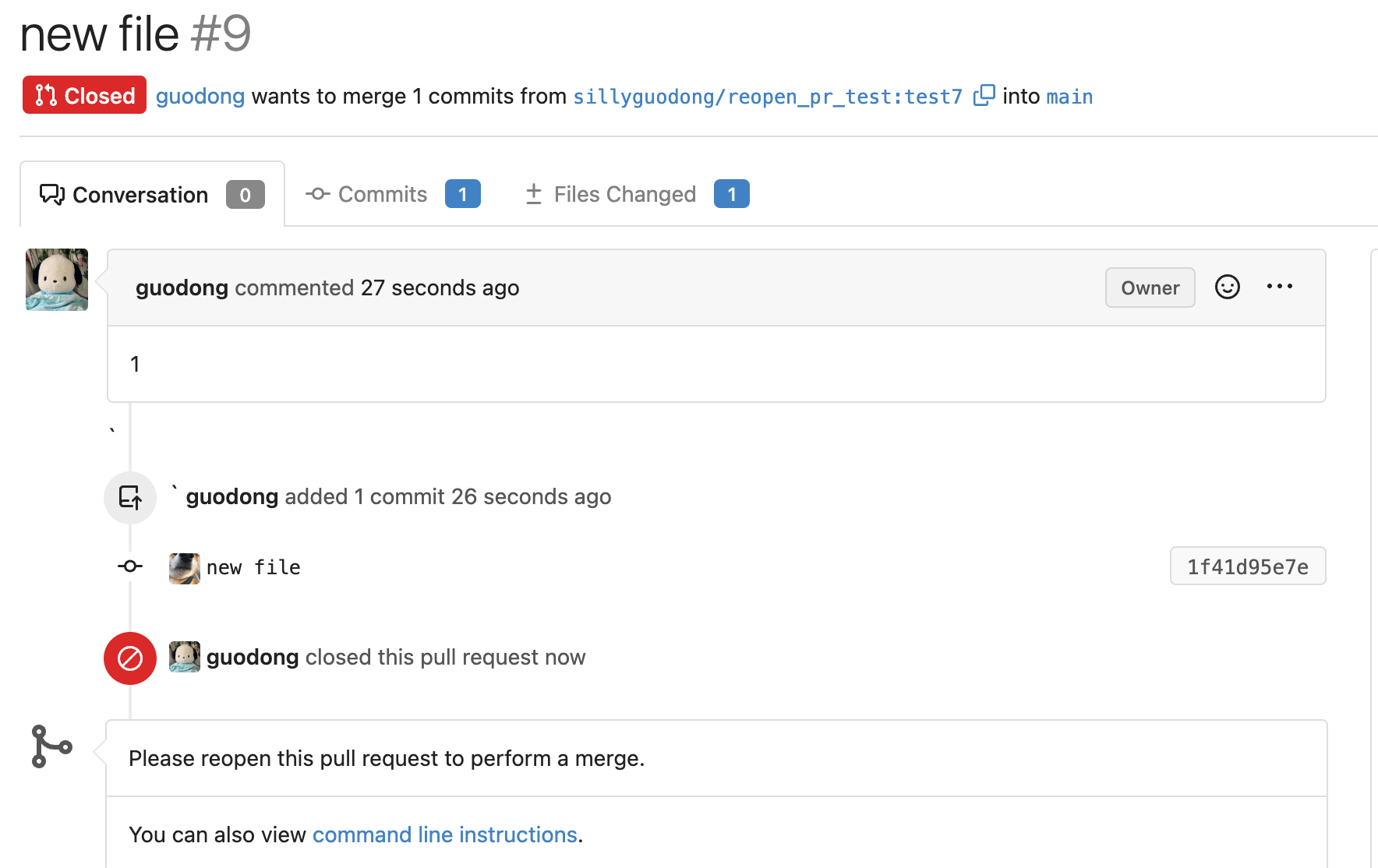
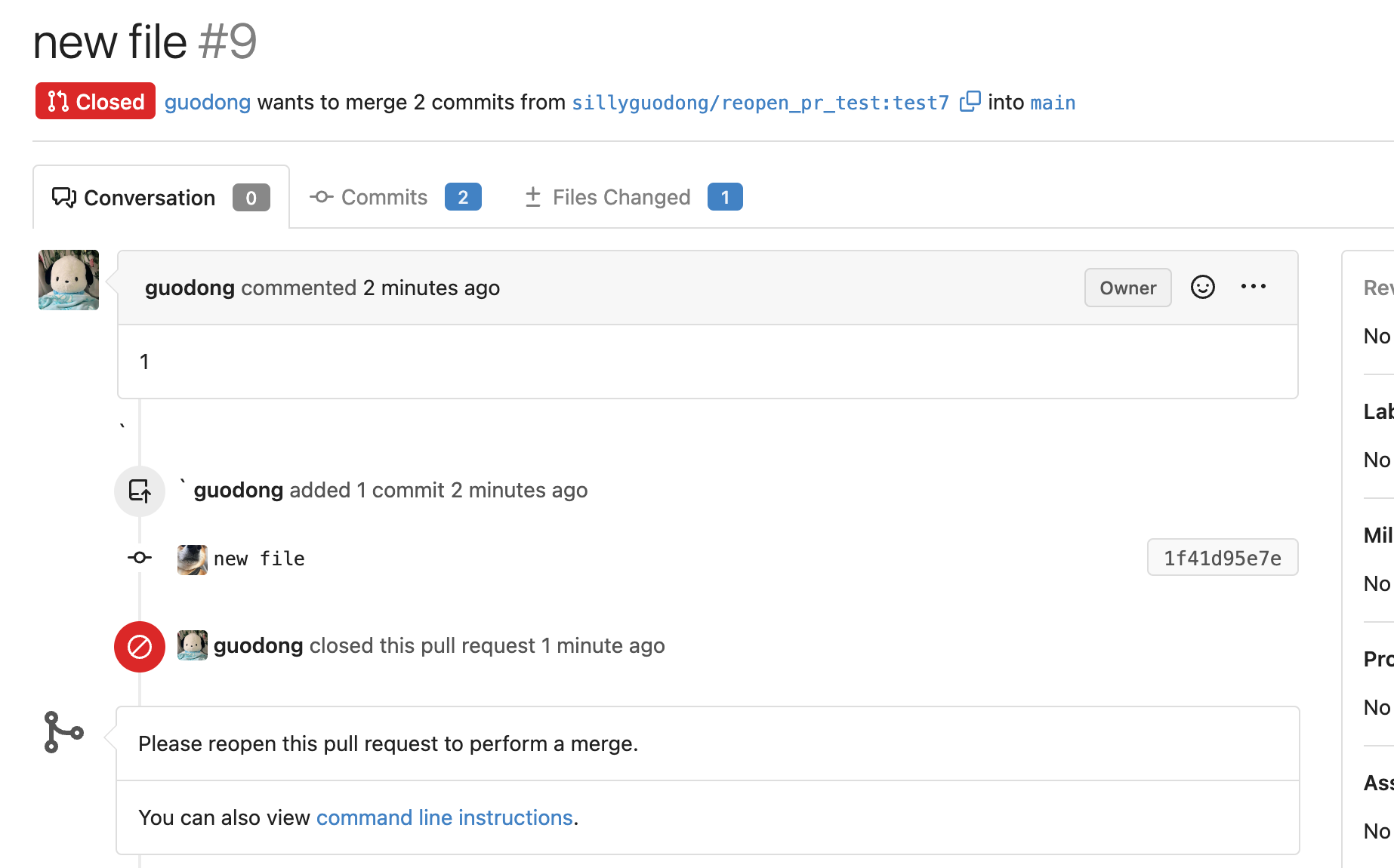
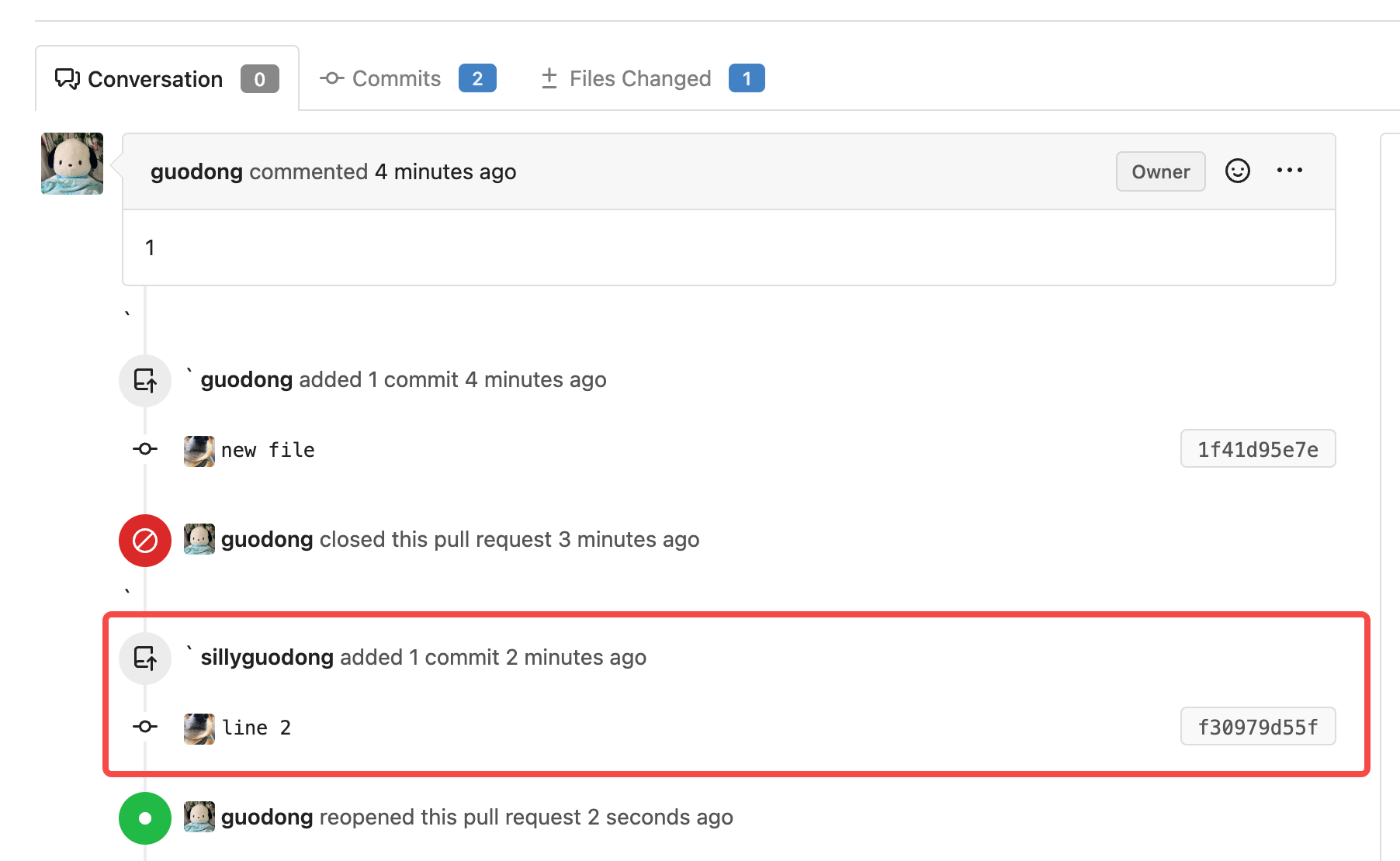
Replace #23830
#### Cause
- Before, in order to making PR can get latest commit after reopening,
the `ref`(${REPO_PATH}/refs/pull/${PR_INDEX}/head) of evrey closed PR
will be updated when pushing commits to the `head branch` of the closed
PR.
#### Changes
- For closed PR , won't perform these behavior: insert`comment`, push
`notification` (UI and email), exectue
[pushToBaseRepo](7422503341/services/pull/pull.go (L409))
function and trigger `action` any more when pushing to the `head branch`
of the closed PR.
- Refresh the reference of the PR when reopening the closed PR (**even
if the head branch has been deleted before**). Make the reference of PR
consistent with the `head branch`.
Close#23440
Cause by #23189
In #23189, we should insert a comment record into db when pushing a
commit to the PR, even if the PR is closed.
But should skip sending any notification in this case.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When emails addresses are private, squash merges always use
`@noreply.localhost` for the author of the squash commit. And the author
is redundantly added as a co-author in the commit message.
Also without private mails, the redundant co-author is possible when
committing with a signature that's different than the user full name and
primary email.
Now try to find a commit by the same user in the list of commits, and
prefer the signature from that over one constructed from the account
settings.
When the base repository contains multiple branches with the same
commits as the base branch, pull requests can show a long list of
commits already in the base branch as having been added.
What this is supposed to do is exclude commits already in the base
branch. But the mechansim to do so assumed a commit only exists in a
single branch. Now use `git rev-list A B --not branchName` instead of
filtering commits afterwards.
The logic to detect if there was a force push also was wrong for
multiple branches. If the old commit existed in any branch in the base
repository it would assume there was no force push. Instead check if the
old commit is an ancestor of the new commit.
Follow #22568
* Remove unnecessary ToTrustedCmdArgs calls
* the FAQ in #22678
* Quote: When using ToTrustedCmdArgs, the code will be very complex (see
the changes for examples). Then developers and reviewers can know that
something might be unreasonable.
* The `signArg` couldn't be empty, it's either `-S{keyID}` or
`--no-gpg-sign`.
* Use `signKeyID` instead, add comment "empty for no-sign, non-empty to
sign"
* 5-line code could be extracted to a common `NewGitCommandCommit()` to
handle the `signKeyID`, but I think it's not a must, current code is
clear enough.
The merge and update branch code was previously a little tangled and had
some very long functions. The functions were not very clear in their
reasoning and there were deficiencies in their logging and at least one
bug in the handling of LFS for update by rebase.
This PR substantially refactors this code and splits things out to into
separate functions. It also attempts to tidy up the calls by wrapping
things in "context"s. There are also attempts to improve logging when
there are errors.
Signed-off-by: Andrew Thornton <art27@cantab.net>
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: delvh <dev.lh@web.de>
Close#23241
Before: press Ctrl+Enter in the Code Review Form, a single comment will
be added.
After: press Ctrl+Enter in the Code Review Form, start the review with
pending comments.
The old name `is_review` is not clear, so the new code use
`pending_review` as the new name.
Co-authored-by: delvh <leon@kske.dev>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
When fetching remotes for conflict checking, skip unnecessary and
potentially slow writing of commit graphs.
In a test with the Blender repository, this reduces conflict checking
time for one pull request from about 2s to 0.1s.
Close #23027
`git commit` message option _only_ supports 4 formats (well, only ....):
* `"commit", "-m", msg`
* `"commit", "-m{msg}"` (no space)
* `"commit", "--message", msg`
* `"commit", "--message={msg}"`
The long format with `=` is the best choice, and it's documented in `man
git-commit`:
`-m <msg>, --message=<msg> ...`
ps: I would suggest always use long format option for git command, as
much as possible.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}