This is a large and complex PR, so let me explain in detail its changes.
First, I had to create new index mappings for Bleve and ElasticSerach as
the current ones do not support search by filename. This requires Gitea
to recreate the code search indexes (I do not know if this is a breaking
change, but I feel it deserves a heads-up).
I've used [this
approach](https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-pathhierarchy-tokenizer.html)
to model the filename index. It allows us to efficiently search for both
the full path and the name of a file. Bleve, however, does not support
this out-of-box, so I had to code a brand new [token
filter](https://blevesearch.com/docs/Token-Filters/) to generate the
search terms.
I also did an overhaul in the `indexer_test.go` file. It now asserts the
order of the expected results (this is important since matches based on
the name of a file are more relevant than those based on its content).
I've added new test scenarios that deal with searching by filename. They
use a new repo included in the Gitea fixture.
The screenshot below depicts how Gitea shows the search results. It
shows results based on content in the same way as the current version
does. In matches based on the filename, the first seven lines of the
file contents are shown (BTW, this is how GitHub does it).

Resolves#32096
---------
Signed-off-by: Bruno Sofiato <bruno.sofiato@gmail.com>
Misspell 0.5.0 supports passing a csv file to extend the list of
misspellings, so I added some common ones from the codebase. There is at
least one typo in a API response so we need to decided whether to revert
that and then likely remove the dict entry.
On creation of an empty project (no template) a default board will be
created instead of falling back to the uneditable pseudo-board.
Every project now has to have exactly one default boards. As a
consequence, you cannot unset a board as default, instead you have to
set another board as default. Existing projects will be modified using a
cron job, additionally this check will run every midnight by default.
Deleting the default board is not allowed, you have to set another board
as default to do it.
Fixes#29873Fixes#14679 along the way
Fixes#29853
Co-authored-by: delvh <dev.lh@web.de>
Refactor the webhook logic, to have the type-dependent processing happen
only in one place.
---
## Current webhook flow
1. An event happens
2. It is pre-processed (depending on the webhook type) and its body is
added to a task queue
3. When the task is processed, some more logic (depending on the webhook
type as well) is applied to make an HTTP request
This means that webhook-type dependant logic is needed in step 2 and 3.
This is cumbersome and brittle to maintain.
Updated webhook flow with this PR:
1. An event happens
2. It is stored as-is and added to a task queue
3. When the task is processed, the event is processed (depending on the
webhook type) to make an HTTP request
So the only webhook-type dependent logic happens in one place (step 3)
which should be much more robust.
## Consequences of the refactor
- the raw event must be stored in the hooktask (until now, the
pre-processed body was stored)
- to ensure that previous hooktasks are correctly sent, a
`payload_version` is added (version 1: the body has already been
pre-process / version 2: the body is the raw event)
So future webhook additions will only have to deal with creating an
http.Request based on the raw event (no need to adjust the code in
multiple places, like currently).
Moreover since this processing happens when fetching from the task
queue, it ensures that the queuing of new events (upon a `git push` for
instance) does not get slowed down by a slow webhook.
As a concrete example, the PR #19307 for custom webhooks, should be
substantially smaller:
- no need to change `services/webhook/deliver.go`
- minimal change in `services/webhook/webhook.go` (add the new webhook
to the map)
- no need to change all the individual webhook files (since with this
refactor the `*webhook_model.Webhook` is provided as argument)
Fix for regressions introduced by #28805
Enabled projects on repos created before the PR weren't detected. Also,
the way projects mode was detected in settings didn't match the way it
was detected on permission check, which leads to confusion.
Co-authored-by: Giteabot <teabot@gitea.io>
Part of #23318
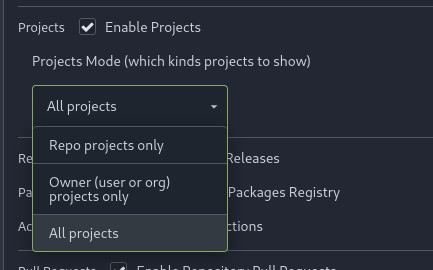
Add menu in repo settings to allow for repo admin to decide not just if
projects are enabled or disabled per repo, but also which kind of
projects (repo-level/owner-level) are enabled. If repo projects
disabled, don't show the projects tab.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fix#14459
The following users can add/remove review requests of a PR
- the poster of the PR
- the owner or collaborators of the repository
- members with read permission on the pull requests unit
Adds a new API `/repos/{owner}/{repo}/commits/{sha}/pull` that allows
you to get the merged PR associated to a commit.
---------
Co-authored-by: 6543 <6543@obermui.de>
Fixes#28660
Fixes an admin api bug related to `user.LoginSource`
Fixed `/user/emails` response not identical to GitHub api
This PR unifies the user update methods. The goal is to keep the logic
only at one place (having audit logs in mind). For example, do the
password checks only in one method not everywhere a password is updated.
After that PR is merged, the user creation should be next.
Fixes#22236
---
Error occurring currently while trying to revert commit using read-tree
-m approach:
> 2022/12/26 16:04:43 ...rvices/pull/patch.go:240:AttemptThreeWayMerge()
[E] [63a9c61a] Unable to run read-tree -m! Error: exit status 128 -
fatal: this operation must be run in a work tree
> - fatal: this operation must be run in a work tree
We need to clone a non-bare repository for `git read-tree -m` to work.
bb371aee6e
adds support to create a non-bare cloned temporary upload repository.
After cloning a non-bare temporary upload repository, we [set default
index](https://github.com/go-gitea/gitea/blob/main/services/repository/files/cherry_pick.go#L37)
(`git read-tree HEAD`).
This operation ends up resetting the git index file (see investigation
details below), due to which, we need to call `git update-index
--refresh` afterward.
Here's the diff of the index file before and after we execute
SetDefaultIndex: https://www.diffchecker.com/hyOP3eJy/
Notice the **ctime**, **mtime** are set to 0 after SetDefaultIndex.
You can reproduce the same behavior using these steps:
```bash
$ git clone https://try.gitea.io/me-heer/test.git -s -b main
$ cd test
$ git read-tree HEAD
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
error: Entry '1' not uptodate. Cannot merge.
```
After which, we can fix like this:
```
$ git update-index --refresh
$ git read-tree -m 1f085d7ed8 1f085d7ed8 9933caed00
```
Unfortunately, when a system setting hasn't been stored in the database,
it cannot be cached.
Meanwhile, this PR also uses context cache for push email avatar display
which should avoid to read user table via email address again and again.
According to my local test, this should reduce dashboard elapsed time
from 150ms -> 80ms .
> ### Description
> If a new branch is pushed, and the repository has a rule that would
require signed commits for the new branch, the commit is rejected with a
500 error regardless of whether it's signed.
>
> When pushing a new branch, the "old" commit is the empty ID
(0000000000000000000000000000000000000000). verifyCommits has no
provision for this and passes an invalid commit range to git rev-list.
Prior to 1.19 this wasn't an issue because only pre-existing individual
branches could be protected.
>
> I was able to reproduce with
[try.gitea.io/CraigTest/test](https://try.gitea.io/CraigTest/test),
which is set up with a blanket rule to require commits on all branches.
Fix#25565
Very thanks to @Craig-Holmquist-NTI for reporting the bug and suggesting
an valid solution!
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
## Archived labels
This adds the structure to allow for archived labels.
Archived labels are, just like closed milestones or projects, a medium to hide information without deleting it.
It is especially useful if there are outdated labels that should no longer be used without deleting the label entirely.
## Changes
1. UI and API have been equipped with the support to mark a label as archived
2. The time when a label has been archived will be stored in the DB
## Outsourced for the future
There's no special handling for archived labels at the moment.
This will be done in the future.
## Screenshots


Part of https://github.com/go-gitea/gitea/issues/25237
---------
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
- The permalink and 'Reference in New issue' URL of an renderable file
(those where you can see the source and a rendered version of it, such
as markdown) doesn't contain `?display=source`. This leads the issue
that the URL doesn't have any effect, as by default the rendered version
is shown and thus not the source.
- Add `?display=source` to the permalink URL and to 'Reference in New
Issue' if it's renderable file.
- Add integration testing.
Refs: https://codeberg.org/forgejo/forgejo/pulls/1088
Co-authored-by: Gusted <postmaster@gusted.xyz>
Co-authored-by: Giteabot <teabot@gitea.io>
Fix#25934
Add `ignoreGlobal` parameter to `reqUnitAccess` and only check global
disabled units when `ignoreGlobal` is true. So the org-level projects
and user-level projects won't be affected by global disabled
`repo.projects` unit.
Fixes (?) #25538
Fixes https://codeberg.org/forgejo/forgejo/issues/972
Regression #23879#23879 introduced a change which prevents read access to packages if a
user is not a member of an organization.
That PR also contained a change which disallows package access if the
team unit is configured with "no access" for packages. I don't think
this change makes sense (at the moment). It may be relevant for private
orgs. But for public or limited orgs that's useless because an
unauthorized user would have more access rights than the team member.
This PR restores the old behaviour "If a user has read access for an
owner, they can read packages".
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Fix#25558
Extract from #22743
This PR added a repository's check when creating/deleting branches via
API. Mirror repository and archive repository cannot do that.
Related #14180
Related #25233
Related #22639Close#19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Enable deduplication of unofficial reviews. When pull requests are
configured to include all approvers, not just official ones, in the
default merge messages it was possible to generate duplicated
Reviewed-by lines for a single person. Add an option to find only
distinct reviews for a given query.
fixes#24795
---------
Signed-off-by: Cory Todd <cory.todd@canonical.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Fixes#24145
To solve the bug, I added a "computed" `TargetBehind` field to the
`Release` model, which indicates the target branch of a release.
This is particularly useful if the target branch was deleted in the
meantime (or is empty).
I also did a micro-optimization in `calReleaseNumCommitsBehind`. Instead
of checking that a branch exists and then call `GetBranchCommit`, I
immediately call `GetBranchCommit` and handle the `git.ErrNotExist`
error.
This optimization is covered by the added unit test.
At first, we have one unified team unit permission which is called
`Team.Authorize` in DB.
But since https://github.com/go-gitea/gitea/pull/17811, we allowed
different units to have different permission.
The old code is only designed for the old version. So after #17811, if
org users have write permission of other units, but have no permission
of packages, they can also get write permission of packages.
Co-authored-by: delvh <dev.lh@web.de>
`namedBlob` turned out to be a poor imitation of a `TreeEntry`. Using
the latter directly shortens this code.
This partially undoes https://github.com/go-gitea/gitea/pull/23152/,
which I found a merge conflict with, and also expands the test it added
to cover the subtle README-in-a-subfolder case.
Add test coverage to the important features of
[`routers.web.repo.renderReadmeFile`](067b0c2664/routers/web/repo/view.go (L273));
namely that:
- it can handle looking in docs/, .gitea/, and .github/
- it can handle choosing between multiple competing READMEs
- it prefers the localized README to the markdown README to the
plaintext README
- it can handle broken symlinks when processing all the options
- it uses the name of the symlink, not the name of the target of the
symlink
`renderReadmeFile` needs `readmeTreelink` as parameter but gets
`treeLink`.
The values of them look like as following:
`treeLink`: `/{OwnerName}/{RepoName}/src/branch/{BranchName}`
`readmeTreelink`:
`/{OwnerName}/{RepoName}/src/branch/{BranchName}/{ReadmeFileName}`
`path.Dir` in
8540fc45b1/routers/web/repo/view.go (L316)
should convert `readmeTreelink` into
`/{OwnerName}/{RepoName}/src/branch/{BranchName}` instead of the current
`/{OwnerName}/{RepoName}/src/branch`.
Fixes#23151
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
During the recent hash algorithm change it became clear that the choice
of password hash algorithm plays a role in the time taken for CI to run.
Therefore as attempt to improve CI we should consider using a dummy
hashing algorithm instead of a real hashing algorithm.
This PR creates a dummy algorithm which is then set as the default
hashing algorithm during tests that use the fixtures. This hopefully
will cause a reduction in the time it takes for CI to run.
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}