feat: eetq gemv optimization when batch_size <= 4 (#1502)
# What does this PR do? <!-- Congratulations! You've made it this far! You're not quite done yet though. Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution. Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change. Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost. --> <!-- Remove if not applicable --> Add TensorRT-LLM weight-only GEMV kernel support. We extract GEMV kernel from [TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM/tree/main/cpp/tensorrt_llm/kernels/weightOnlyBatchedGemv) to accelerate the decode speed of EETQ when batch_size is smaller or equal to 4. - Features 1. There is almost no loss of quantization accuracy. 2. The speed of decoding is 13% - 27% faster than original EETQ which utilizes GEMM kernel. - Test Below is our test on 3090. Environment: torch=2.0.1, cuda=11.8, nvidia driver: 525.78.01 prompt=1024, max_new_tokens=50  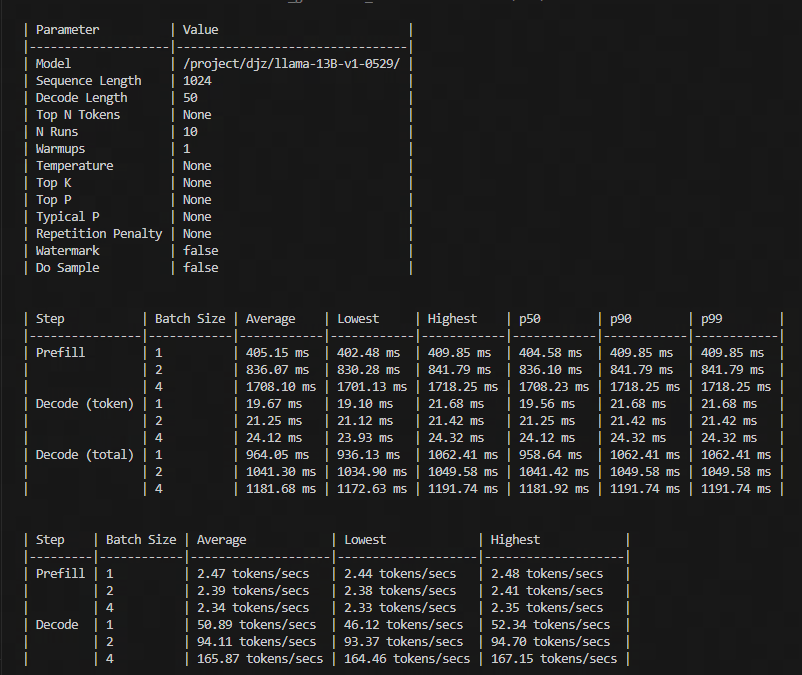 ## Before submitting - [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). - [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section? - [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case. - [ ] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation). - [ ] Did you write any new necessary tests? ## Who can review? Anyone in the community is free to review the PR once the tests have passed. Feel free to tag members/contributors who may be interested in your PR. <!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @ @OlivierDehaene OR @Narsil -->
This commit is contained in:
parent
2d56f106a6
commit
0595bf3e9a
|
|
@ -1,4 +1,4 @@
|
|||
eetq_commit := 323827dd471458a84e9c840f614e4592b157a4b1
|
||||
eetq_commit := 71adb5e191bb8290069a580abff0355d7b2dd5c9
|
||||
|
||||
eetq:
|
||||
# Clone eetq
|
||||
|
|
@ -6,7 +6,7 @@ eetq:
|
|||
git clone https://github.com/NetEase-FuXi/EETQ.git eetq
|
||||
|
||||
build-eetq: eetq
|
||||
cd eetq && git fetch && git checkout $(eetq_commit)
|
||||
cd eetq && git fetch && git checkout $(eetq_commit) && git submodule update --init --recursive
|
||||
cd eetq && python setup.py build
|
||||
|
||||
install-eetq: build-eetq
|
||||
|
|
|
|||
Loading…
Reference in New Issue