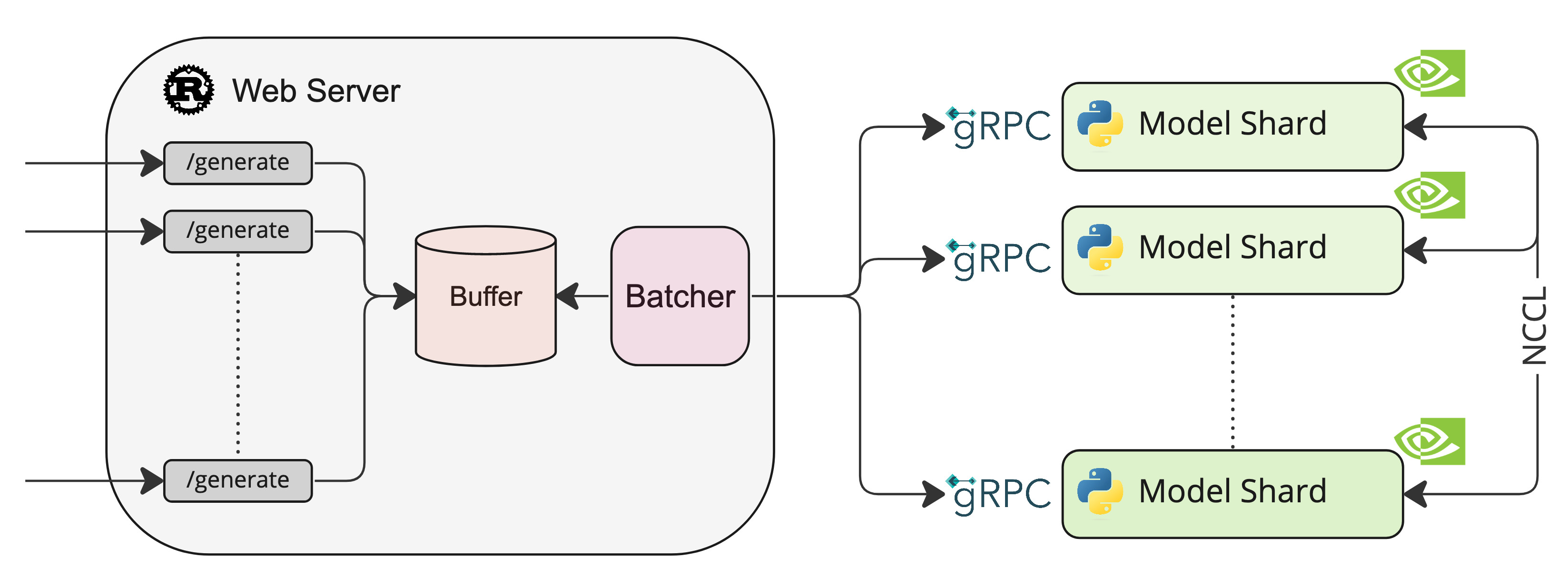
# Text Generation Inference