|
|
||
|---|---|---|
| .github/workflows | ||
| aml | ||
| assets | ||
| docs | ||
| k6 | ||
| launcher | ||
| proto | ||
| router | ||
| server | ||
| .dockerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Dockerfile | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| rust-toolchain.toml | ||
README.md
Text Generation Inference


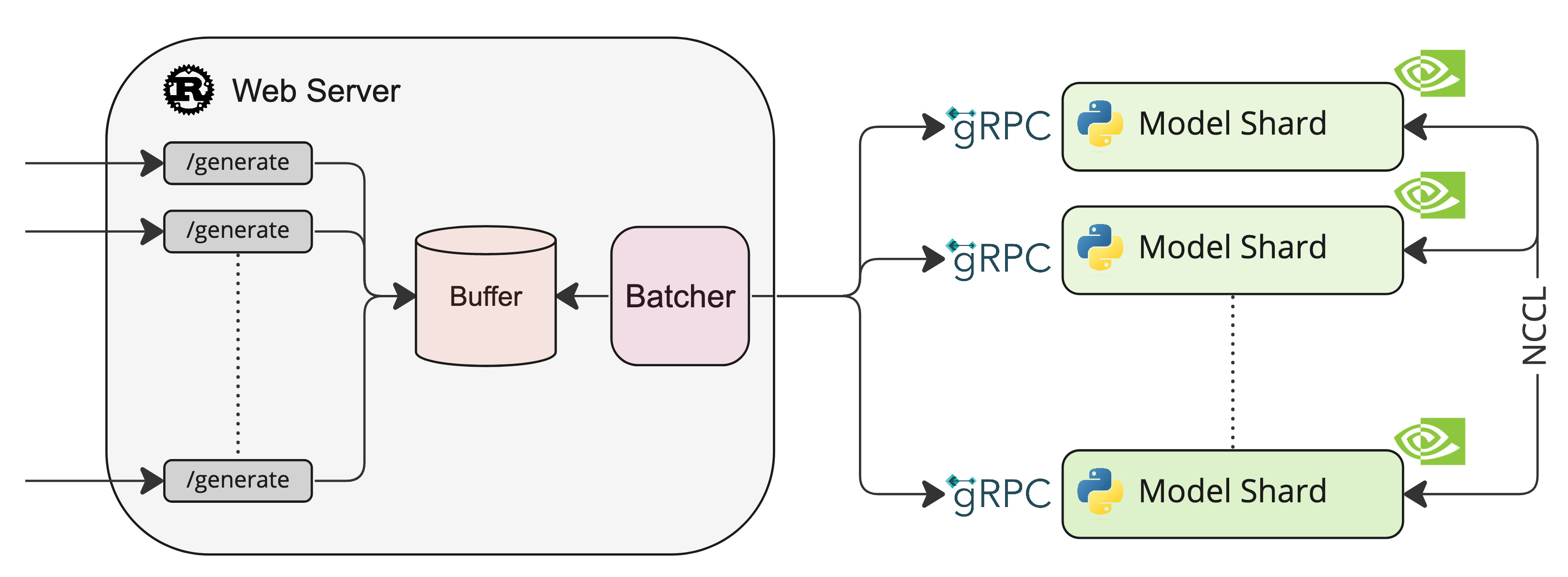
A Rust, Python and gRPC server for text generation inference. Used in production at HuggingFace to power LLMs api-inference widgets.
Table of contents
Features
- Token streaming using Server Side Events (SSE)
- Dynamic batching of incoming requests for increased total throughput
- Quantization with bitsandbytes
- Safetensors weight loading
- 45ms per token generation for BLOOM with 8xA100 80GB
- Logits warpers (temperature scaling, topk, repetition penalty ...)
- Stop sequences
- Log probabilities
Officially supported models
- BLOOM
- BLOOMZ
- MT0-XXL
Galactica(deactivated)- SantaCoder
- GPT-Neox 20B
- FLAN-T5-XXL
Other models are supported on a best effort basis using:
AutoModelForCausalLM.from_pretrained(<model>, device_map="auto")
or
AutoModelForSeq2SeqLM.from_pretrained(<model>, device_map="auto")
Get started
Docker
The easiest way of getting started is using the official Docker container:
model=bigscience/bloom-560m
num_shard=2
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --num-shard $num_shard
You can then query the model using either the /generate or /generate_stream routes:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"Testing API","parameters":{"max_new_tokens":9}}' \
-H 'Content-Type: application/json'
curl 127.0.0.1:8080/generate_stream \
-X POST \
-d '{"inputs":"Testing API","parameters":{"max_new_tokens":9}}' \
-H 'Content-Type: application/json'
Note: To use GPUs, you need to install the NVIDIA Container Toolkit.
API documentation
You can consult the OpenAPI documentation of the text-generation-inference REST API using the /docs route.
The Swagger UI is also available at: https://huggingface.github.io/text-generation-inference.
A note on Shared Memory (shm)
NCCL is a communication framework used by
PyTorch to do distributed training/inference. text-generation-inference make
use of NCCL to enable Tensor Parallelism to dramatically speed up inference for large language models.
In order to share data between the different devices of a NCCL group, NCCL might fall back to using the host memory if
peer-to-peer using NVLink or PCI is not possible.
To allow the container to use 1G of Shared Memory and support SHM sharing, we add --shm-size 1g on the above command.
If you are running text-generation-inference inside Kubernetes. You can also add Shared Memory to the container by
creating a volume with:
- name: shm
emptyDir:
medium: Memory
sizeLimit: 1Gi
and mounting it to /dev/shm.
Finally, you can also disable SHM sharing by using the NCCL_SHM_DISABLE=1 environment variable. However, note that
this will impact performance.
Local install
You can also opt to install text-generation-inference locally.
First install Rust and create a Python virtual environment with at least
Python 3.9, e.g. using conda:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
conda create -n text-generation-inference python=3.9
conda activate text-generation-inference
Then run:
BUILD_EXTENSIONS=True make install # Install repository and HF/transformer fork with CUDA kernels
make run-bloom-560m
Note: on some machines, you may also need the OpenSSL libraries and gcc. On Linux machines, run:
sudo apt-get install libssl-dev gcc -y
CUDA Kernels
The custom CUDA kernels are only tested on NVIDIA A100s. If you have any installation or runtime issues, you can remove
the kernels by using the BUILD_EXTENSIONS=False environment variable.
Be aware that the official Docker image has them enabled by default.
Run BLOOM
Download
First you need to download the weights:
make download-bloom
Run
make run-bloom # Requires 8xA100 80GB
Quantization
You can also quantize the weights with bitsandbytes to reduce the VRAM requirement:
make run-bloom-quantize # Requires 8xA100 40GB
Develop
make server-dev
make router-dev
Testing
make python-tests
make integration-tests