|
|
||
|---|---|---|
| aml | ||
| assets | ||
| k6 | ||
| launcher | ||
| proto | ||
| router | ||
| server | ||
| .dockerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Dockerfile | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| rust-toolchain.toml | ||
README.md
LLM Text Generation Inference
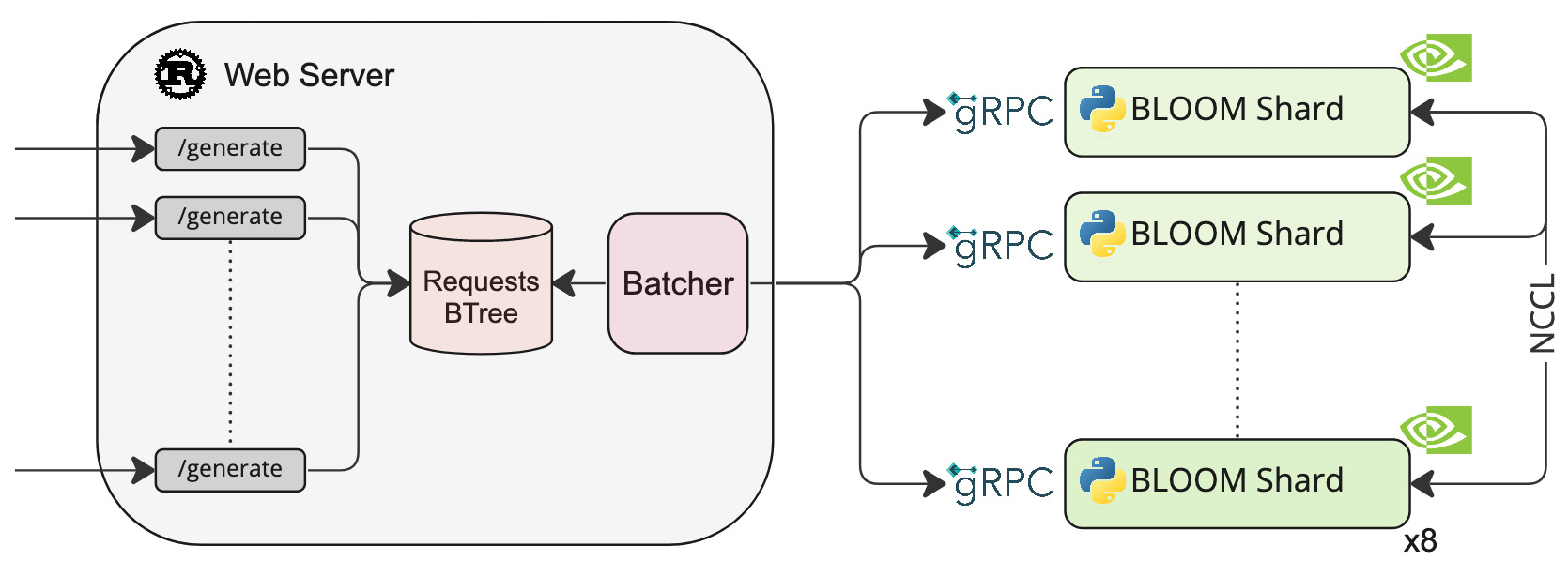
A Rust and gRPC server for large language models text generation inference.
Features
- Quantization with bitsandbytes
- Dynamic bathing of incoming requests for increased total throughput
- Safetensors weight loading
- 45ms per token generation for BLOOM with 8xA100 80GB
Officially supported models
- BLOOM
- BLOOM-560m
Other models are supported on a best-effort basis using AutoModelForCausalLM.from_pretrained(<model>, torch_dtype=torch.float16, device_map="auto").
Load Tests for BLOOM
See k6/load_test.js
| avg | min | med | max | p(90) | p(95) | RPS | |
|---|---|---|---|---|---|---|---|
| Original code | 8.9s | 1s | 9.12s | 16.69s | 13.7s | 14.26s | 5.9 |
| New batching logic | 5.44s | 959.53ms | 5.28s | 13.12s | 7.78s | 8.92s | 9.08 |
Install
make install
Run
BLOOM 560-m
make run-bloom-560m
BLOOM
First you need to download the weights:
make download-bloom
make run-bloom # Requires 8xA100 80GB
You can also quantize the weights with bitsandbytes to reduce the VRAM requirement:
make run-bloom-quantize # Requires 8xA100 40GB
Test
curl 127.0.0.1:3000/generate \
-v \
-X POST \
-d '{"inputs":"Testing API","parameters":{"max_new_tokens":9}}' \
-H 'Content-Type: application/json'
Develop
make server-dev
make router-dev
TODO:
- Add tests for the
server/modellogic - Backport custom CUDA kernels to Transformers
- Install safetensors with pip