This change adds support for prefix caching to the v3 router. This is broken up from the backend support to ease reviewing. For now prefix caching is only enabled with `USE_PREFIX_CACHING=1` in this case, the router will switch to `RadixAllocator`. This allocator uses a radix trie to keep track of prefills that were seen prior. If a new prefill is a prefix of a previously-seen prefil, the router will send a request with `prefix_len>0`, which can be used by the backend to decide to reuse KV blocks from the cache, rather than recomputing them. Even though backend support is not added in this PR, the backend will still work with prefix caching enabled. The prefix lengths are just ignored and not used. |
||
|---|---|---|
| .. | ||
| src | ||
| Cargo.toml | ||
| README.md | ||
README.md
Text Generation Inference benchmarking tool
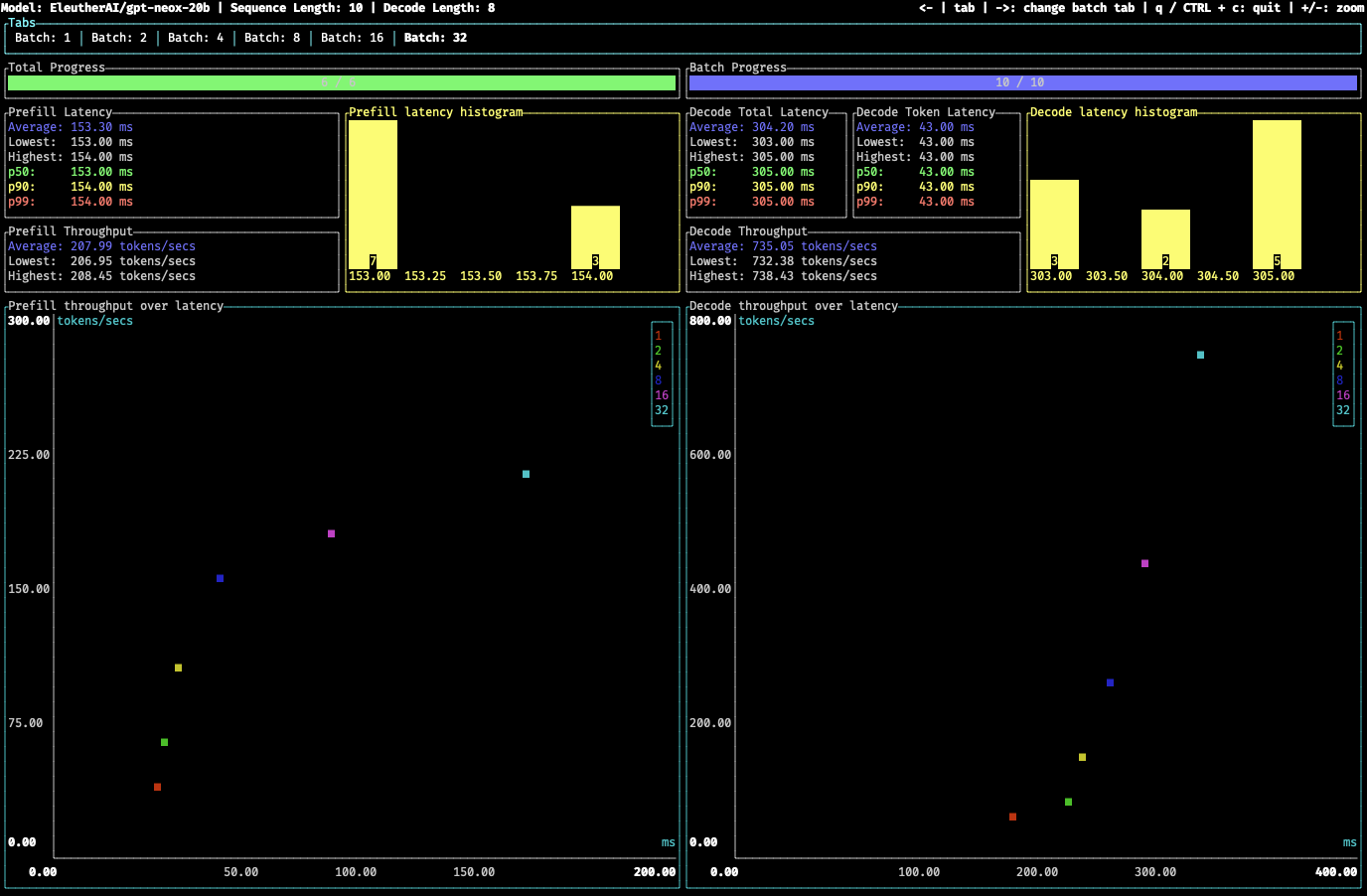
A lightweight benchmarking tool based inspired by oha and powered by tui.
Install
make install-benchmark
Run
First, start text-generation-inference:
text-generation-launcher --model-id bigscience/bloom-560m
Then run the benchmarking tool:
text-generation-benchmark --tokenizer-name bigscience/bloom-560m