Co-authored-by: OlivierDehaene <23298448+OlivierDehaene@users.noreply.github.com> |
||
|---|---|---|
| aml | ||
| assets | ||
| k6 | ||
| launcher | ||
| proto | ||
| router | ||
| server | ||
| .dockerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Dockerfile | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| rust-toolchain.toml | ||
README.md
LLM Text Generation Inference
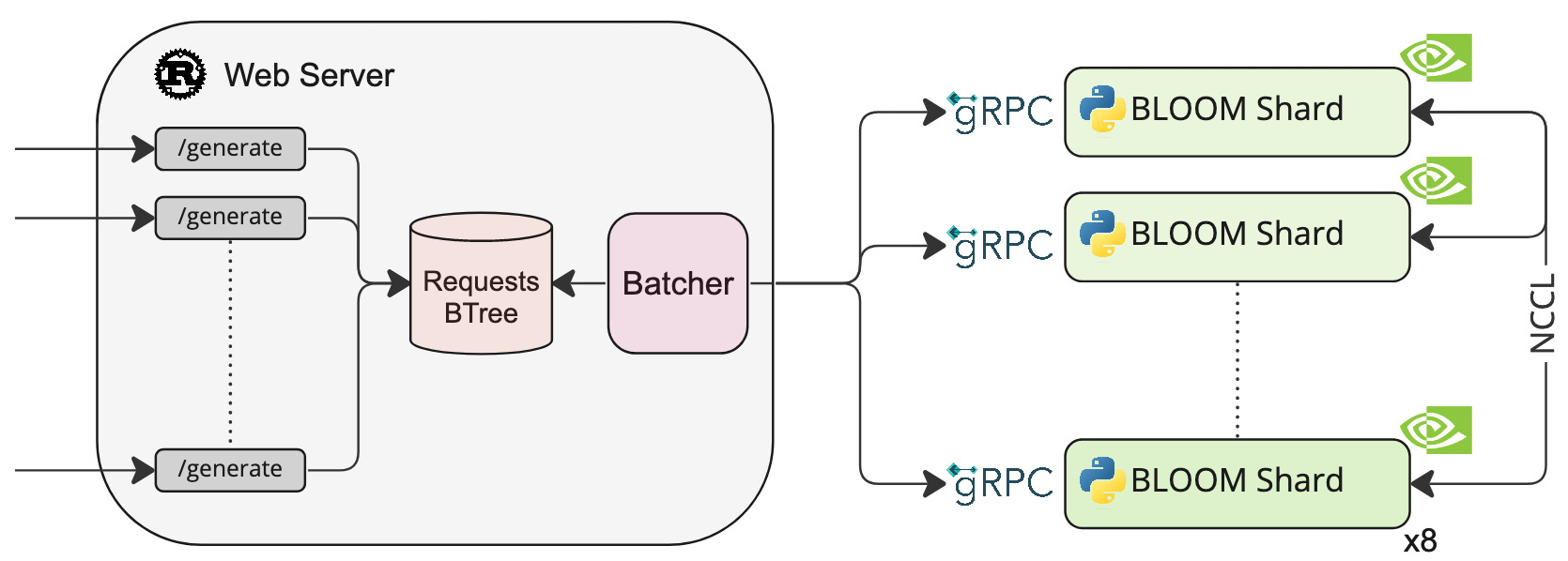
A Rust and gRPC server for large language models text generation inference.
Load Tests for BLOOM
See k6/load_test.js
We send the default examples with a 1 second delay between requests.
Stages:
- Ramp up to 50 vus in 1min
- Ramp up from 50 to 100 vus in 2min
- Ramp down to 0 vus in 1min
| avg | min | med | max | p(90) | p(95) | RPS | |
|---|---|---|---|---|---|---|---|
| Original code | 8.9s | 1s | 9.12s | 16.69s | 13.7s | 14.26s | 5.9 |
| ISO with original code | 8.88s | 959.53ms | 8.89s | 17.08s | 13.34s | 14.12s | 5.94 |
| New batching logic | 5.44s | 1.27s | 5.28s | 13.12s | 7.78s | 8.92s | 9.08 |
Install
make install
Run
make run-bloom-560m
Test
curl 127.0.0.1:3000/generate \
-v \
-X POST \
-d '{"inputs":"Testing API","parameters":{"max_new_tokens":9}}' \
-H 'Content-Type: application/json'
Develop
make server-dev
make router-dev
TODO:
- Add tests for the
server/modellogic - Backport custom CUDA kernels to Transformers
- Install safetensors with pip