This WIP PR starts to add grammar support via outlines, currently this PR supports very simple regex grammars and does not optimize for precompiling or caching grammar fsm's. todo: - [X] add simple outlines guidance to `NextTokenChooser` - [X] update protos for grammar - [X] update generation params API - [X] constrain simple grammar - [ ] support parsing more complex grammar into fsm - [ ] support all outline support grammar types - [ ] explore optimizations to avoid recompiling grammars guided request ```bash curl -s 'http://localhost:3000/generate' \ --header 'Content-Type: application/json' \ --data-raw '{ "inputs": "make an email for david: \n", "parameters": { "max_new_tokens": 6, "grammar": "[\\w-]+@([\\w-]+\\.)+[\\w-]+" } }' | jq ``` response ```json { "generated_text": "david@example.com" } ``` unguided request ```bash curl -s 'http://localhost:3000/generate' \ --header 'Content-Type: application/json' \ --data '{ "inputs": "make an email for david: \n", "parameters": { "max_new_tokens": 6 } }' | jq ``` response ```json { "generated_text": " email = 'david" } ``` |
||
|---|---|---|
| .. | ||
| src | ||
| Cargo.toml | ||
| README.md | ||
README.md
Text Generation Inference benchmarking tool
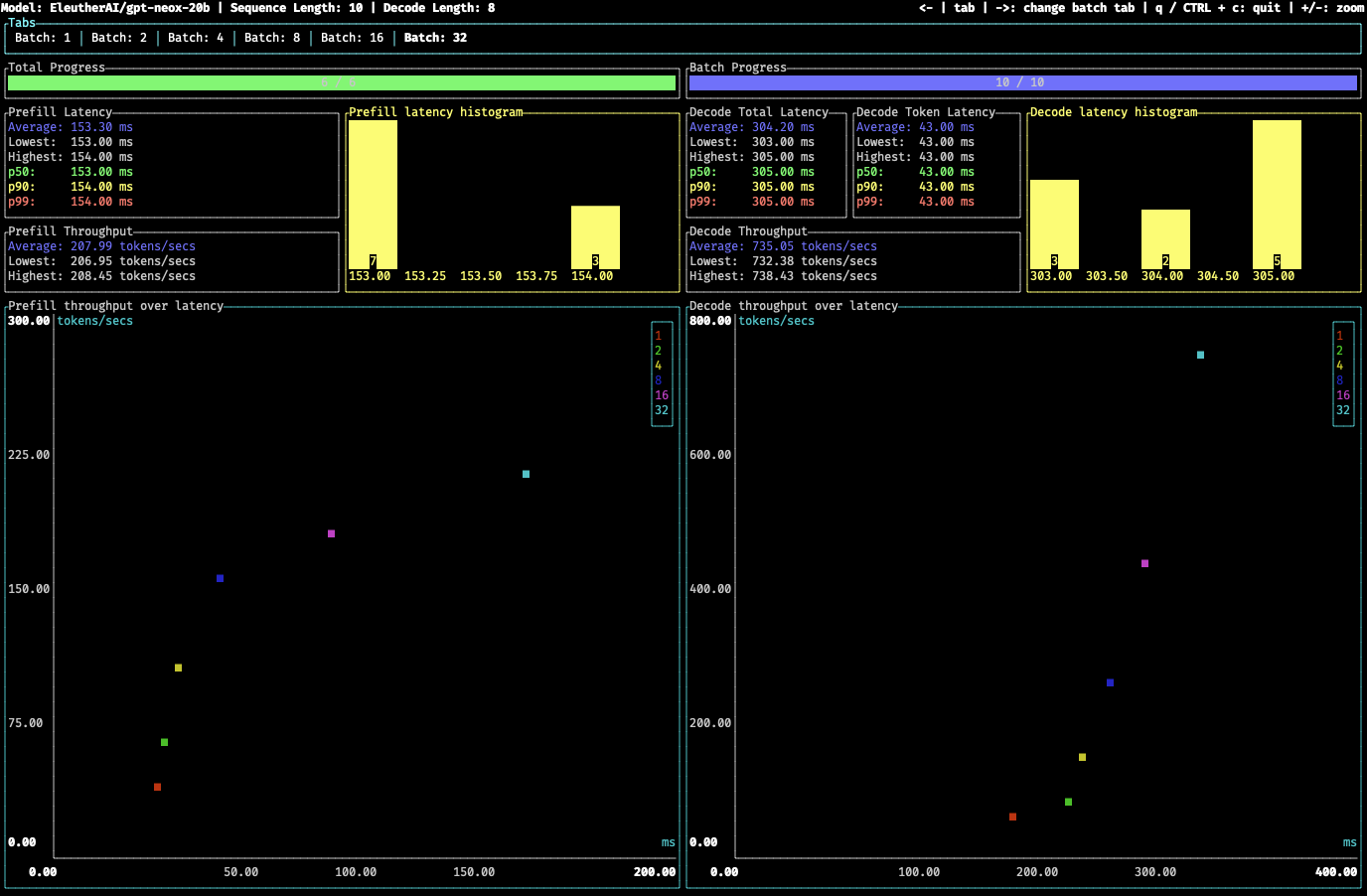
A lightweight benchmarking tool based inspired by oha and powered by tui.
Install
make install-benchmark
Run
First, start text-generation-inference:
text-generation-launcher --model-id bigscience/bloom-560m
Then run the benchmarking tool:
text-generation-benchmark --tokenizer-name bigscience/bloom-560m