# What does this PR do? It solves a typo in the comment sections referencing the environment variable `CUDA_VISIBLE_DEVICES`. No misspelling references to this variable have been found in code logic leading to undefined behaviour or bugs. This PR is not expected to perform any code logic modification. |
||
|---|---|---|
| .github | ||
| aml | ||
| assets | ||
| benchmark | ||
| clients/python | ||
| docs | ||
| integration-tests | ||
| launcher | ||
| load_tests | ||
| proto | ||
| router | ||
| server | ||
| .dockerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Dockerfile | ||
| LICENSE | ||
| Makefile | ||
| README.md | ||
| rust-toolchain.toml | ||
| sagemaker-entrypoint.sh | ||
README.md
Text Generation Inference


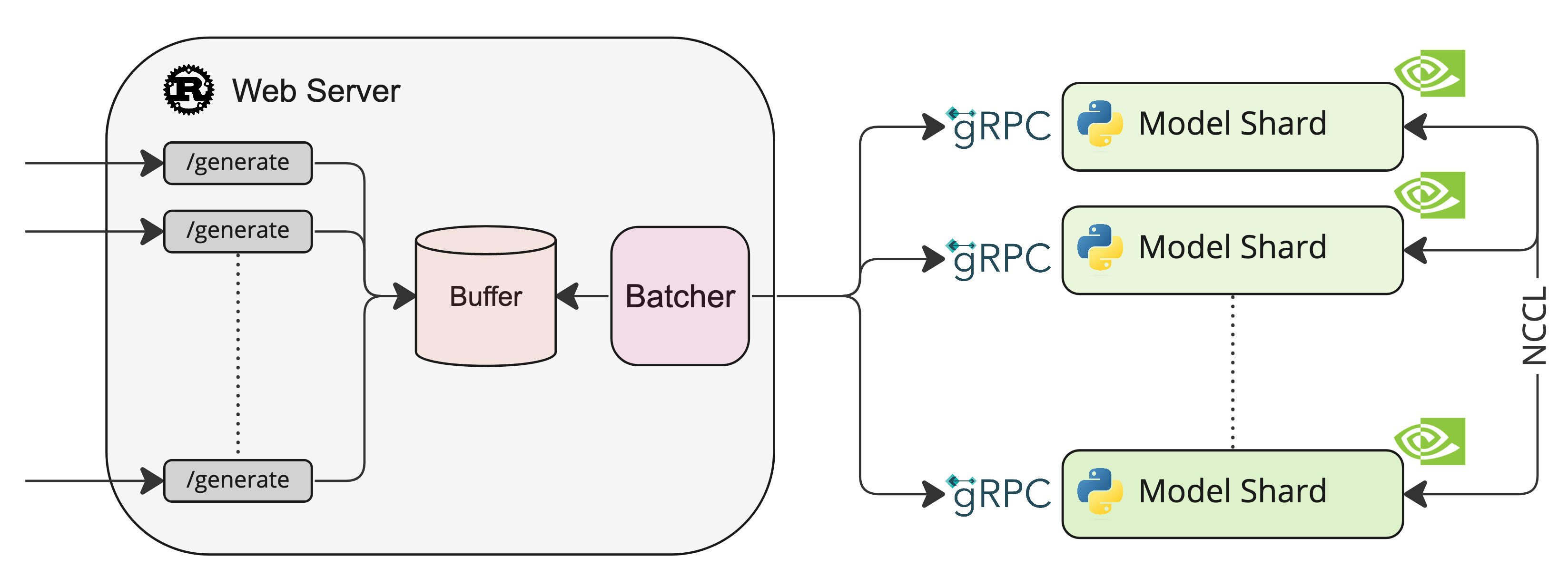
A Rust, Python and gRPC server for text generation inference. Used in production at HuggingFace to power LLMs api-inference widgets.
Table of contents
Features
- Serve the most popular Large Language Models with a simple launcher
- Tensor Parallelism for faster inference on multiple GPUs
- Token streaming using Server-Sent Events (SSE)
- Continuous batching of incoming requests for increased total throughput
- Optimized transformers code for inference using flash-attention on the most popular architectures
- Quantization with bitsandbytes
- Safetensors weight loading
- Watermarking with A Watermark for Large Language Models
- Logits warper (temperature scaling, top-p, top-k, repetition penalty, more details see transformers.LogitsProcessor)
- Stop sequences
- Log probabilities
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
Optimized architectures
Other architectures are supported on a best effort basis using:
AutoModelForCausalLM.from_pretrained(<model>, device_map="auto")
or
AutoModelForSeq2SeqLM.from_pretrained(<model>, device_map="auto")
Get started
Docker
The easiest way of getting started is using the official Docker container:
model=bigscience/bloom-560m
num_shard=2
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:0.8 --model-id $model --num-shard $num_shard
Note: To use GPUs, you need to install the NVIDIA Container Toolkit. We also recommend using NVIDIA drivers with CUDA version 11.8 or higher.
To see all options to serve your models (in the code or in the cli:
text-generation-launcher --help
You can then query the model using either the /generate or /generate_stream routes:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17}}' \
-H 'Content-Type: application/json'
curl 127.0.0.1:8080/generate_stream \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17}}' \
-H 'Content-Type: application/json'
or from Python:
pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
print(client.generate("What is Deep Learning?", max_new_tokens=17).generated_text)
text = ""
for response in client.generate_stream("What is Deep Learning?", max_new_tokens=17):
if not response.token.special:
text += response.token.text
print(text)
API documentation
You can consult the OpenAPI documentation of the text-generation-inference REST API using the /docs route.
The Swagger UI is also available at: https://huggingface.github.io/text-generation-inference.
Distributed Tracing
text-generation-inference is instrumented with distributed tracing using OpenTelemetry. You can use this feature
by setting the address to an OTLP collector with the --otlp-endpoint argument.
A note on Shared Memory (shm)
NCCL is a communication framework used by
PyTorch to do distributed training/inference. text-generation-inference make
use of NCCL to enable Tensor Parallelism to dramatically speed up inference for large language models.
In order to share data between the different devices of a NCCL group, NCCL might fall back to using the host memory if
peer-to-peer using NVLink or PCI is not possible.
To allow the container to use 1G of Shared Memory and support SHM sharing, we add --shm-size 1g on the above command.
If you are running text-generation-inference inside Kubernetes. You can also add Shared Memory to the container by
creating a volume with:
- name: shm
emptyDir:
medium: Memory
sizeLimit: 1Gi
and mounting it to /dev/shm.
Finally, you can also disable SHM sharing by using the NCCL_SHM_DISABLE=1 environment variable. However, note that
this will impact performance.
Local install
You can also opt to install text-generation-inference locally.
First install Rust and create a Python virtual environment with at least
Python 3.9, e.g. using conda:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
conda create -n text-generation-inference python=3.9
conda activate text-generation-inference
You may also need to install Protoc.
On Linux:
PROTOC_ZIP=protoc-21.12-linux-x86_64.zip
curl -OL https://github.com/protocolbuffers/protobuf/releases/download/v21.12/$PROTOC_ZIP
sudo unzip -o $PROTOC_ZIP -d /usr/local bin/protoc
sudo unzip -o $PROTOC_ZIP -d /usr/local 'include/*'
rm -f $PROTOC_ZIP
On MacOS, using Homebrew:
brew install protobuf
Then run:
BUILD_EXTENSIONS=True make install # Install repository and HF/transformer fork with CUDA kernels
make run-bloom-560m
Note: on some machines, you may also need the OpenSSL libraries and gcc. On Linux machines, run:
sudo apt-get install libssl-dev gcc -y
CUDA Kernels
The custom CUDA kernels are only tested on NVIDIA A100s. If you have any installation or runtime issues, you can remove
the kernels by using the BUILD_EXTENSIONS=False environment variable.
Be aware that the official Docker image has them enabled by default.
Run BLOOM
Download
It is advised to download the weights ahead of time with the following command:
make download-bloom
Run
make run-bloom # Requires 8xA100 80GB
Quantization
You can also quantize the weights with bitsandbytes to reduce the VRAM requirement:
make run-bloom-quantize # Requires 8xA100 40GB
Develop
make server-dev
make router-dev
Testing
# python
make python-server-tests
make python-client-tests
# or both server and client tests
make python-tests
# rust cargo tests
make rust-tests
# integration tests
make integration-tests