Separate `MAX_OUTPUT_TOKENS` config for OpenAI/Claude (khanon/oai-reverse-proxy!21)
This commit is contained in:
parent
a6a0c21f7d
commit
120040c028
|
|
@ -4,7 +4,8 @@
|
|||
# PORT=7860
|
||||
# SERVER_TITLE=Coom Tunnel
|
||||
# MODEL_RATE_LIMIT=4
|
||||
# MAX_OUTPUT_TOKENS=300
|
||||
# MAX_OUTPUT_TOKENS_OPENAI=300
|
||||
# MAX_OUTPUT_TOKENS_ANTHROPIC=900
|
||||
# LOG_LEVEL=info
|
||||
# REJECT_DISALLOWED=false
|
||||
# REJECT_MESSAGE="This content violates /aicg/'s acceptable use policy."
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
.env
|
||||
.venv
|
||||
.vscode
|
||||
build
|
||||
greeting.md
|
||||
node_modules
|
||||
venv
|
||||
|
|
|
|||
|
|
@ -4,6 +4,7 @@ This repository can be deployed to a [Huggingface Space](https://huggingface.co/
|
|||
|
||||
### 1. Get an API key
|
||||
- Go to [OpenAI](https://openai.com/) and sign up for an account. You can use a free trial key for this as long as you provide SMS verification.
|
||||
- Claude is not publicly available yet, but if you have access to it via the [Anthropic](https://www.anthropic.com/) closed beta, you can also use that key with the proxy.
|
||||
|
||||
### 2. Create an empty Huggingface Space
|
||||
- Go to [Huggingface](https://huggingface.co/) and sign up for an account.
|
||||
|
|
@ -35,13 +36,15 @@ CMD [ "npm", "start" ]
|
|||
|
||||

|
||||
|
||||
### 4. Set your OpenAI API key as a secret
|
||||
### 4. Set your API key as a secret
|
||||
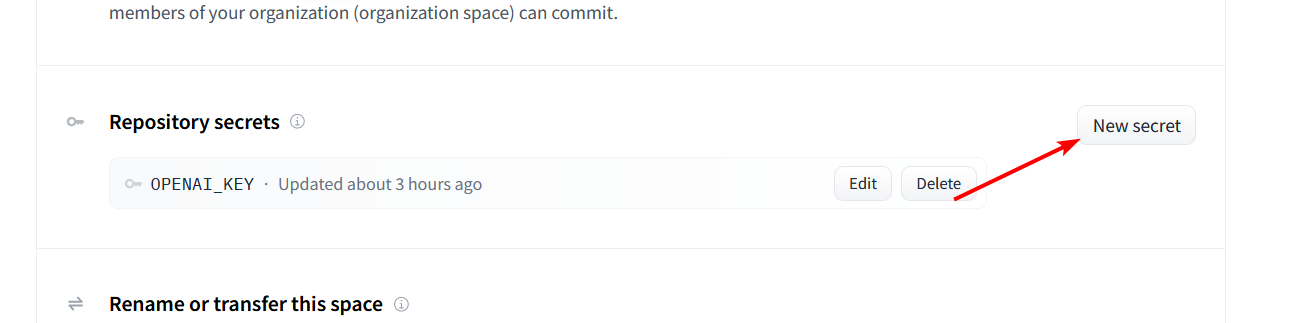
- Click the Settings button in the top right corner of your repository.
|
||||
- Scroll down to the `Repository Secrets` section and click `New Secret`.
|
||||
|
||||
|
||||
|
||||
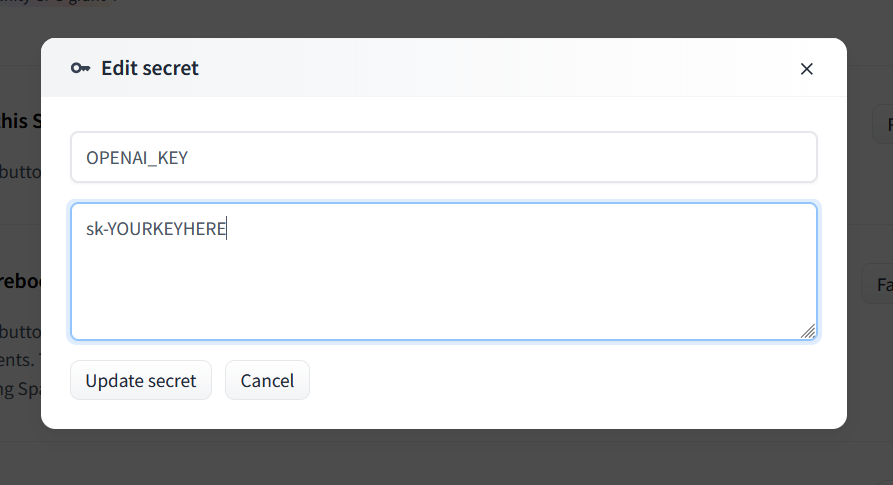
- Enter `OPENAI_KEY` as the name and your OpenAI API key as the value.
|
||||
- For Claude, set `ANTHROPIC_KEY` instead.
|
||||
- You can use both types of keys at the same time if you want.
|
||||
|
||||
|
||||
|
||||
|
|
@ -49,8 +52,8 @@ CMD [ "npm", "start" ]
|
|||
- Your server should automatically deploy when you add the secret, but if not you can select `Factory Reboot` from that same Settings menu.
|
||||
|
||||
### 6. Share the link
|
||||
- The Service Info section below should show the URL for your server. You can share this with anyone to safely give them access to your OpenAI API key.
|
||||
- Your friend doesn't need any OpenAI API key of their own, they just need your link.
|
||||
- The Service Info section below should show the URL for your server. You can share this with anyone to safely give them access to your API key.
|
||||
- Your friend doesn't need any API key of their own, they just need your link.
|
||||
|
||||
# Optional
|
||||
|
||||
|
|
@ -71,12 +74,16 @@ The server will be started with some default configuration, but you can override
|
|||
Here are some example settings:
|
||||
```shell
|
||||
# Requests per minute per IP address
|
||||
MODEL_RATE_LIMIT=2
|
||||
MODEL_RATE_LIMIT=4
|
||||
# Max tokens to request from OpenAI
|
||||
MAX_OUTPUT_TOKENS=256
|
||||
MAX_OUTPUT_TOKENS_OPENAI=256
|
||||
# Max tokens to request from Anthropic (Claude)
|
||||
MAX_OUTPUT_TOKENS_ANTHROPIC=512
|
||||
# Block prompts containing disallowed characters
|
||||
REJECT_DISALLOWED=false
|
||||
REJECT_MESSAGE="This content violates /aicg/'s acceptable use policy."
|
||||
# Show exact quota usage on the Server Info page
|
||||
QUOTA_DISPLAY_MODE=full
|
||||
```
|
||||
|
||||
See `.env.example` for a full list of available settings, or check `config.ts` for details on what each setting does.
|
||||
|
|
|
|||
|
|
@ -1,7 +1,11 @@
|
|||
import dotenv from "dotenv";
|
||||
import type firebase from "firebase-admin";
|
||||
import pino from "pino";
|
||||
dotenv.config();
|
||||
|
||||
// Can't import the usual logger here because it itself needs the config.
|
||||
const startupLogger = pino({ level: "debug" }).child({ module: "startup" });
|
||||
|
||||
const isDev = process.env.NODE_ENV !== "production";
|
||||
|
||||
type PromptLoggingBackend = "google_sheets";
|
||||
|
|
@ -59,8 +63,10 @@ type Config = {
|
|||
maxIpsPerUser: number;
|
||||
/** Per-IP limit for requests per minute to OpenAI's completions endpoint. */
|
||||
modelRateLimit: number;
|
||||
/** Max number of tokens to generate. Requests which specify a higher value will be rewritten to use this value. */
|
||||
maxOutputTokens: number;
|
||||
/** For OpenAI, the maximum number of sampled tokens a user can request. */
|
||||
maxOutputTokensOpenAI: number;
|
||||
/** For Anthropic, the maximum number of sampled tokens a user can request. */
|
||||
maxOutputTokensAnthropic: number;
|
||||
/** Whether requests containing disallowed characters should be rejected. */
|
||||
rejectDisallowed?: boolean;
|
||||
/** Message to return when rejecting requests. */
|
||||
|
|
@ -129,7 +135,11 @@ export const config: Config = {
|
|||
firebaseRtdbUrl: getEnvWithDefault("FIREBASE_RTDB_URL", undefined),
|
||||
firebaseKey: getEnvWithDefault("FIREBASE_KEY", undefined),
|
||||
modelRateLimit: getEnvWithDefault("MODEL_RATE_LIMIT", 4),
|
||||
maxOutputTokens: getEnvWithDefault("MAX_OUTPUT_TOKENS", 300),
|
||||
maxOutputTokensOpenAI: getEnvWithDefault("MAX_OUTPUT_TOKENS_OPENAI", 300),
|
||||
maxOutputTokensAnthropic: getEnvWithDefault(
|
||||
"MAX_OUTPUT_TOKENS_ANTHROPIC",
|
||||
600
|
||||
),
|
||||
rejectDisallowed: getEnvWithDefault("REJECT_DISALLOWED", false),
|
||||
rejectMessage: getEnvWithDefault(
|
||||
"REJECT_MESSAGE",
|
||||
|
|
@ -154,8 +164,35 @@ export const config: Config = {
|
|||
blockRedirect: getEnvWithDefault("BLOCK_REDIRECT", "https://www.9gag.com"),
|
||||
} as const;
|
||||
|
||||
function migrateConfigs() {
|
||||
let migrated = false;
|
||||
const deprecatedMax = process.env.MAX_OUTPUT_TOKENS;
|
||||
|
||||
if (!process.env.MAX_OUTPUT_TOKENS_OPENAI && deprecatedMax) {
|
||||
migrated = true;
|
||||
config.maxOutputTokensOpenAI = parseInt(deprecatedMax);
|
||||
}
|
||||
if (!process.env.MAX_OUTPUT_TOKENS_ANTHROPIC && deprecatedMax) {
|
||||
migrated = true;
|
||||
config.maxOutputTokensAnthropic = parseInt(deprecatedMax);
|
||||
}
|
||||
|
||||
if (migrated) {
|
||||
startupLogger.warn(
|
||||
{
|
||||
MAX_OUTPUT_TOKENS: deprecatedMax,
|
||||
MAX_OUTPUT_TOKENS_OPENAI: config.maxOutputTokensOpenAI,
|
||||
MAX_OUTPUT_TOKENS_ANTHROPIC: config.maxOutputTokensAnthropic,
|
||||
},
|
||||
"`MAX_OUTPUT_TOKENS` has been replaced with separate `MAX_OUTPUT_TOKENS_OPENAI` and `MAX_OUTPUT_TOKENS_ANTHROPIC` configs. You should update your .env file to remove `MAX_OUTPUT_TOKENS` and set the new configs."
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
/** Prevents the server from starting if config state is invalid. */
|
||||
export async function assertConfigIsValid() {
|
||||
migrateConfigs();
|
||||
|
||||
// Ensure gatekeeper mode is valid.
|
||||
if (!["none", "proxy_key", "user_token"].includes(config.gatekeeper)) {
|
||||
throw new Error(
|
||||
|
|
|
|||
|
|
@ -3,34 +3,32 @@ import { config } from "../../../config";
|
|||
import { isCompletionRequest } from "../common";
|
||||
import { ProxyRequestMiddleware } from ".";
|
||||
|
||||
const MAX_TOKENS = config.maxOutputTokens;
|
||||
|
||||
/** Enforce a maximum number of tokens requested from the model. */
|
||||
export const limitOutputTokens: ProxyRequestMiddleware = (_proxyReq, req) => {
|
||||
// TODO: do all of this shit in the zod validator
|
||||
if (isCompletionRequest(req)) {
|
||||
const requestedMaxTokens = Number.parseInt(getMaxTokensFromRequest(req));
|
||||
let maxTokens = requestedMaxTokens;
|
||||
const requestedMax = Number.parseInt(getMaxTokensFromRequest(req));
|
||||
const apiMax =
|
||||
req.outboundApi === "openai"
|
||||
? config.maxOutputTokensOpenAI
|
||||
: config.maxOutputTokensAnthropic;
|
||||
let maxTokens = requestedMax;
|
||||
|
||||
if (typeof requestedMaxTokens !== "number") {
|
||||
req.log.warn(
|
||||
{ requestedMaxTokens, clampedMaxTokens: MAX_TOKENS },
|
||||
"Invalid max tokens value. Using default value."
|
||||
);
|
||||
maxTokens = MAX_TOKENS;
|
||||
if (typeof requestedMax !== "number") {
|
||||
maxTokens = apiMax;
|
||||
}
|
||||
|
||||
// TODO: this is not going to scale well, need to implement a better way
|
||||
// of translating request parameters from one API to another.
|
||||
maxTokens = Math.min(maxTokens, MAX_TOKENS);
|
||||
maxTokens = Math.min(maxTokens, apiMax);
|
||||
if (req.outboundApi === "openai") {
|
||||
req.body.max_tokens = maxTokens;
|
||||
} else if (req.outboundApi === "anthropic") {
|
||||
req.body.max_tokens_to_sample = maxTokens;
|
||||
}
|
||||
|
||||
if (requestedMaxTokens !== maxTokens) {
|
||||
req.log.warn(
|
||||
`Limiting max tokens from ${requestedMaxTokens} to ${maxTokens}`
|
||||
if (requestedMax !== maxTokens) {
|
||||
req.log.info(
|
||||
{ requestedMax, configMax: apiMax, final: maxTokens },
|
||||
"Limiting user's requested max output tokens"
|
||||
);
|
||||
}
|
||||
}
|
||||
|
|
|
|||
Loading…
Reference in New Issue