organize
This commit is contained in:
parent
d6b9e9ddd9
commit
4a5e84afff
22
README.md
22
README.md
|
|
@ -4,25 +4,31 @@ _Google Colab notebooks ported to standard Jupiter for Paperspace._
|
||||||
|
|
||||||
Don't post bug reports on the Kazakhstan rock collection forum. Create an issue here.
|
Don't post bug reports on the Kazakhstan rock collection forum. Create an issue here.
|
||||||
|
|
||||||
|
|
||||||
### Getting Started
|
### Getting Started
|
||||||
|
|
||||||
[Docs/Paperspace Guide for Idiots.md](https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/Docs/Paperspace%20Guide%20for%20Retards.md)
|
[Docs/Paperspace Guide for Idiots.md](https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/Docs/Paperspace%20Guide%20for%20Retards.md)
|
||||||
|
|
||||||
### Notebook Descriptions
|
### Notebook Descriptions
|
||||||
|
|
||||||
**StableDiffusionUI_Voldemort_paperspace.ipynb**
|
#### StableDiffusionUI_Voldemort_paperspace.ipynb
|
||||||
|
|
||||||
Voldemort's webUI. His repository is updated frequently so the notebook will update the local copy if it's already installed. Can run the normal model or waifu-diffusion.
|
AUTOMATIC1111's webUI. Designed to get a newbie set up, features lots of error checking and automation.
|
||||||
|
|
||||||
|
#### Cyberes_Textual_Inversion_Training.ipynb
|
||||||
|
|
||||||
|
All the commands you need to do create a textual inversion embedding. Does not hold your hand or guide you through the process. Any issues related to this notebook will be closed.
|
||||||
|
|
||||||
**CodeFormer_Inference_Simplified.ipynb**
|
#### lfs/latent-diffusion
|
||||||
|
|
||||||
CodeFormer face fixer standalone. Can process images in bulk.
|
Holds stuff for latent-diffusion. Probably not needed but latent-diffusion had them stored on some random file hosting service.
|
||||||
|
|
||||||
|
#### /other Directory
|
||||||
|
|
||||||
|
Other notebooks and code.
|
||||||
|
|
||||||
**stable_diffusion_webui_hlky_paperspace_09-07-2022.ipynb**
|
- CodeFormer_Inference_Simplified.ipynb
|
||||||
|
- stable_diffusion_webui_hlky_paperspace_09-07-2022.ipynb
|
||||||
hlky's webui
|
- sd-concepts-library_Exporter.ipynb
|
||||||
|
- Huggingface Textual Inversion Training.ipynb
|
||||||
|
- download_sd-concepts-library.py
|
||||||
|
- Misc. old stuff
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,77 @@
|
||||||
|
# Getting Started on Paperspace for Retards <3
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**What is Paperspace?**
|
||||||
|
|
||||||
|
Basically, a cloud compute service for AI development. You run your code on their hardware.
|
||||||
|
|
||||||
|
**Why Paperspace?**
|
||||||
|
|
||||||
|
Paperspace is convenient, free, and you probably don't have a computer good enough to run the AI. They're aimed at professionals whereas Colab is literally for children.
|
||||||
|
|
||||||
|
You'll run your code on their powerful GPUs which is much faster and easier than locally on your computer.
|
||||||
|
|
||||||
|
**Do I have to pay?**
|
||||||
|
|
||||||
|
Only if you feel limited by their free tier. You should have everything you need to generate ~~porn~~ really neat images. I'm pretty Paperspace is cheaper than Google Colab Pro.
|
||||||
|
|
||||||
|
**Why not Google Colab?**
|
||||||
|
|
||||||
|
Google Colab is an alternative, but their free tier is more restrictive than Paperspace's and has less powerful hardware. And, knowing Google, they probably record what you generate.
|
||||||
|
|
||||||
|
**But I want to run it on Google Colab!**
|
||||||
|
|
||||||
|
Ok fine. [Here's the official colab notebook by Voldy himself.](https://colab.research.google.com/drive/1Iy-xW9t1-OQWhb0hNxueGij8phCyluOh)
|
||||||
|
|
||||||
|
**But I'd rather run it on my own computer!**
|
||||||
|
|
||||||
|
Running it in the cloud is much easier and you're less likely to mess up your OS, but since you insist here's a Docker container to make is simpler: [AbdBarho/stable-diffusion-webui-docker](https://github.com/AbdBarho/stable-diffusion-webui-docker)
|
||||||
|
|
||||||
|
## Let's do it!
|
||||||
|
|
||||||
|
1. [Create an Account](https://console.paperspace.com/signup) You will be asked for your phone number. **You can use a VOIP number such as Google Voice, they don't block it!**
|
||||||
|
|
||||||
|
2. Click this button and fill out the form that pops up
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
3. Click this button to create a notebook
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
4. Under "Runtime" select "Start from Stratch"
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
5. Download [StableDiffusionUI_Voldemort_paperspace.ipynb](https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/StableDiffusionUI_Voldemort_paperspace.ipynb)
|
||||||
|
|
||||||
|
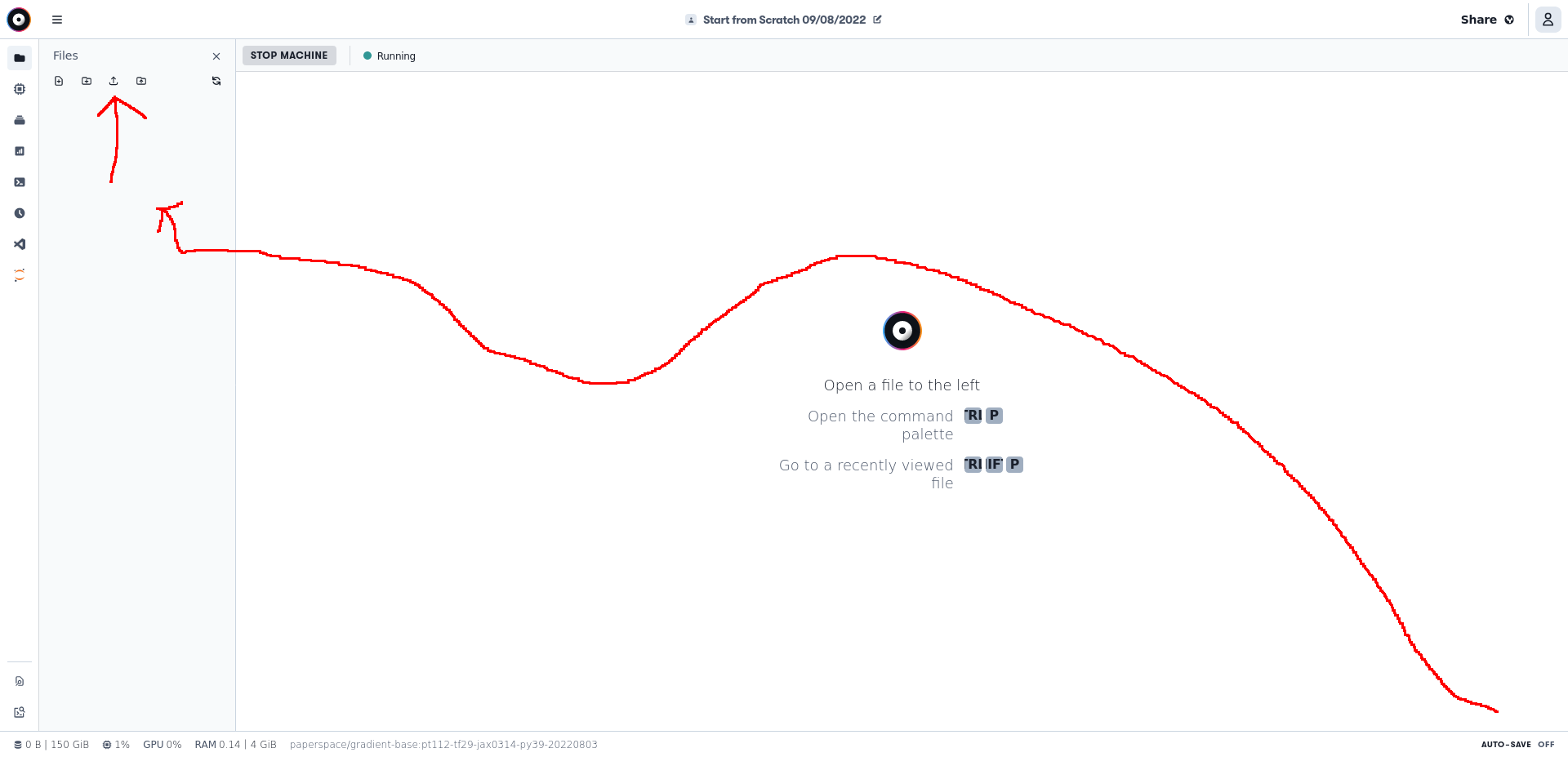
6. Upload that file to your notebook
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
7. Follow directions
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Launch the Jupyter Notebook
|
||||||
|
|
||||||
|
Click this symbol in the left vertical menubar.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
You can access the terminal in the Jupyter Notebook.
|
||||||
|
|
||||||
|
## I need more help :(
|
||||||
|
|
||||||
|
Here's some other guides.
|
||||||
|
|
||||||
|
- [FINAL GUI RETARD GUIDE](https://rentry.org/voldy)
|
||||||
|
- [Using the WebUI](https://rentry.org/voldy)
|
||||||
|
- [Using the Inpainter](https://rentry.org/drfar)
|
||||||
|
- [Textual Inversion](https://rentry.org/aikgx)
|
||||||
|
- [Crowd-Sourced Prompts](https://lexica.art/)
|
||||||
|
- [Artist Name Prompts](https://sgreens.notion.site/sgreens/4ca6f4e229e24da6845b6d49e6b08ae7?v=fdf861d1c65d456e98904fe3f3670bd3)
|
||||||
|
|
||||||
|
[Images hosted on Github](https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace)
|
||||||
|
[Github Mirror](https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/docs/archives/Getting%20Started%20on%20Paperspace.pdf)
|
||||||
|
|
@ -0,0 +1,31 @@
|
||||||
|
# Other
|
||||||
|
|
||||||
|
#### CodeFormer_Inference_Simplified.ipynb
|
||||||
|
|
||||||
|
CodeFormer face fixer standalone. Can process images in bulk.
|
||||||
|
|
||||||
|
#### stable_diffusion_webui_hlky_paperspace_09-07-2022.ipynb
|
||||||
|
|
||||||
|
An alternative to AUTOMATIC1111's WebUI from a guy named hlky. Ported to Paperspace.
|
||||||
|
|
||||||
|
#### sd-concepts-library_Exporter.ipynb
|
||||||
|
|
||||||
|
Download all textual inversion embeddings in huggingface.co/sd-concepts-library. May or may not work.
|
||||||
|
|
||||||
|
#### Huggingface Textual Inversion Training.ipynb
|
||||||
|
|
||||||
|
Train textual inversion embeddings using the HuggingFace API. Doesn't work as well as my `Textual Inversion Training.ipynb` notebook.
|
||||||
|
|
||||||
|
#### download_sd-concepts-library.py
|
||||||
|
|
||||||
|
Basically `sd-concepts-library_Exporter.ipynb` but a Python script. Can download restricted models.
|
||||||
|
|
||||||
|
# Old
|
||||||
|
|
||||||
|
#### voldy's_colab_paperspace_09-07-2022.ipynb
|
||||||
|
|
||||||
|
First iteration of the WebUI for Paperspace.
|
||||||
|
|
||||||
|
#### waifu-diffusion_quick_n_dirty_09-07-2022.ipynb
|
||||||
|
|
||||||
|
Quick 'n dirty notebook made to quickly test Waifu Diffusion the day it was released.
|
||||||
|
|
@ -1,137 +0,0 @@
|
||||||
import argparse
|
|
||||||
import datetime
|
|
||||||
import os
|
|
||||||
import shutil
|
|
||||||
import sys
|
|
||||||
from urllib import request as ulreq
|
|
||||||
|
|
||||||
import requests
|
|
||||||
from huggingface_hub import HfApi
|
|
||||||
from PIL import ImageFile
|
|
||||||
|
|
||||||
|
|
||||||
def getsizes(uri):
|
|
||||||
# https://stackoverflow.com/a/37709319
|
|
||||||
# get file size *and* image size (None if not known)
|
|
||||||
file = ulreq.urlopen(uri)
|
|
||||||
size = file.headers.get("content-length")
|
|
||||||
if size:
|
|
||||||
size = int(size)
|
|
||||||
p = ImageFile.Parser()
|
|
||||||
while True:
|
|
||||||
data = file.read(1024)
|
|
||||||
if not data:
|
|
||||||
break
|
|
||||||
p.feed(data)
|
|
||||||
if p.image:
|
|
||||||
return size, p.image.size
|
|
||||||
break
|
|
||||||
file.close()
|
|
||||||
return (size, None)
|
|
||||||
|
|
||||||
|
|
||||||
parser = argparse.ArgumentParser()
|
|
||||||
parser.add_argument('out_file', nargs='?', help='file to save to')
|
|
||||||
args = parser.parse_args()
|
|
||||||
|
|
||||||
print('Will save to file:', args.out_file)
|
|
||||||
|
|
||||||
# Get list of models under the sd-concepts-library organization
|
|
||||||
print('Getting list of models...')
|
|
||||||
api = HfApi()
|
|
||||||
models_list = []
|
|
||||||
for model in api.list_models(author="sd-concepts-library"):
|
|
||||||
models_list.append(model.modelId.replace('sd-concepts-library/', ''))
|
|
||||||
models_list.sort()
|
|
||||||
|
|
||||||
html_struct = """<!DOCTYPE html>
|
|
||||||
<html lang="en">
|
|
||||||
<head>
|
|
||||||
<title>Stable Diffusion Texual Inversion Models</title>
|
|
||||||
<meta charset="utf-8">
|
|
||||||
<meta name="viewport" content="width=device-width, initial-scale=1">
|
|
||||||
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.2.1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-iYQeCzEYFbKjA/T2uDLTpkwGzCiq6soy8tYaI1GyVh/UjpbCx/TYkiZhlZB6+fzT" crossorigin="anonymous">
|
|
||||||
</head>
|
|
||||||
<body>
|
|
||||||
<style>
|
|
||||||
.img-wrapper {
|
|
||||||
display: flex;
|
|
||||||
margin-top: 40px;
|
|
||||||
}
|
|
||||||
|
|
||||||
.img1,
|
|
||||||
.img2,
|
|
||||||
.img3 {}
|
|
||||||
|
|
||||||
.thumbnail {
|
|
||||||
height: 185px;
|
|
||||||
}
|
|
||||||
|
|
||||||
.model-link {}
|
|
||||||
|
|
||||||
.model-title {
|
|
||||||
margin-top: 100px;
|
|
||||||
}
|
|
||||||
|
|
||||||
.model-link-wrapper {}
|
|
||||||
</style>
|
|
||||||
<div class="container" style="margin-bottom: 180px;">
|
|
||||||
<div class="jumbotron text-center" style="margin: 45px;"><h1>Stable Diffusion Texual Inversion Models</h1></div>
|
|
||||||
<p><i>Page updates daily. Last updated {datetime.datetime.now().strftime("%A, %B %d %Y")}.</i></p>
|
|
||||||
|
|
||||||
<p>
|
|
||||||
Generated from <a href="https://huggingface.co/sd-concepts-library">huggingface.co/sd-concepts-library</a>
|
|
||||||
</p>
|
|
||||||
|
|
||||||
<p>
|
|
||||||
Downloaded models are straight from the HuggingFace repositories and are named learned_embeds.bin. Rename to model_name.pt
|
|
||||||
</p>
|
|
||||||
|
|
||||||
|
|
||||||
<br><hr>
|
|
||||||
"""
|
|
||||||
|
|
||||||
i = 1
|
|
||||||
for model_name in models_list:
|
|
||||||
|
|
||||||
if i == 3:
|
|
||||||
break
|
|
||||||
|
|
||||||
print(f'{i}/{len(models_list)} -> {model_name}')
|
|
||||||
# if os.path.exists(f'{model_name}/learned_embeds.bin'): # double check the file exists since sometimes it hasn't been uploaded yet
|
|
||||||
# shutil.move(f'{model_name}/learned_embeds.bin', f'{model_name}/{model_name}.pt')
|
|
||||||
# pass
|
|
||||||
# else:
|
|
||||||
# continue
|
|
||||||
|
|
||||||
# Images can be in a few different formats, figure out which one it's in
|
|
||||||
img_type = None
|
|
||||||
img_width = None
|
|
||||||
for type in ['jpeg', 'png', 'jpg']:
|
|
||||||
r = requests.head(f'https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/concept_images/0.{type}', allow_redirects=True)
|
|
||||||
if r.status_code == 200:
|
|
||||||
img_type = type
|
|
||||||
img_width = getsizes(f'https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/concept_images/0.{type}')[1][0]
|
|
||||||
break
|
|
||||||
|
|
||||||
html_struct = html_struct + f"""<h3 class="model-title">{model_name}</h3>
|
|
||||||
<p><a class="model-link" href="https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/learned_embeds.bin">Download {model_name}</a></p>
|
|
||||||
<p><a class="model-link" href="https://huggingface.co/sd-concepts-library/{model_name}/">View Repository</a></p>
|
|
||||||
<div class="img-wrapper">
|
|
||||||
<div class="img1" style="width:{img_width}px;">
|
|
||||||
<img class="thumbnail" src="https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/concept_images/0.{img_type}">
|
|
||||||
</div>
|
|
||||||
<div class="img2" style="width:{img_width}px;">
|
|
||||||
<img class="thumbnail" src="https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/concept_images/1.{img_type}">
|
|
||||||
</div>
|
|
||||||
<div class="img3" style="width:{img_width}px;">
|
|
||||||
<img class="thumbnail" src="https://huggingface.co/sd-concepts-library/{model_name}/resolve/main/concept_images/2.{img_type}">
|
|
||||||
</div>
|
|
||||||
</div>"""
|
|
||||||
i = i + 1
|
|
||||||
|
|
||||||
html_struct = html_struct + '</div></body></html>'
|
|
||||||
|
|
||||||
f = open(args.out_file, 'w')
|
|
||||||
f.write(html_struct)
|
|
||||||
f.close()
|
|
||||||
Loading…
Reference in New Issue