4.5 KiB
1. Dataset
In this guide we are going to use the Danbooru2021 dataset by Gwern.net. You are free to use any other dataset as long as you know how to convert it to the right format.
Contents
- Dataset requirements
- Downloading the dataset
- Organizing the dataset
- Packaging the dataset
Dataset requirements
The dataset needs to be in the following format
/dataset/ : Root dataset folder, can be any name
/dataset/img/ : Folder for images
/dataset/txt/ : Folder for text files
It is recommended to have the images in 512x512 resolution and in JPG format. While the text files need to have the same name as the images it refers to.
Foe example:
mydataset
├── img
│ └── image001.jpg
└── txt
└── image001.txt
Where image001.txt has the tags (prompt) to be used for image001.jpg
Downloading the dataset
This is optional; If you have your own dataset skip this part.
Downloading Rsync
Danbooru2021 is available for download through rsync.
Linux
On Linux, you should be able to install rsync via your package manager.
apt install rsync
Windows
On Windows, you are going to need to install Cygwin, a posix runtime for Windows which allows the usage of many linux-only programs inside windows.
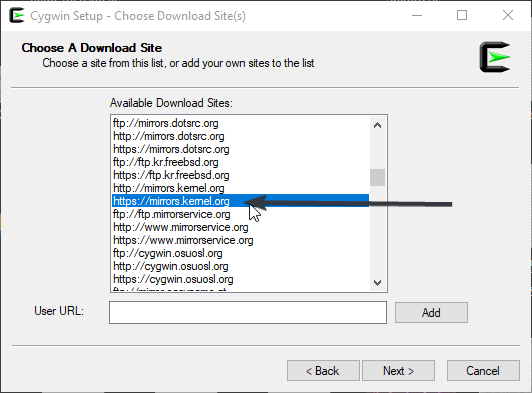
On the installer, select mirrors.kernel.org for Download Site:
Next, search for "rsync" on the search bar, change "View: Pending" to "View: Full", and select on the "New" tab the latest version. Do the same for "zip".
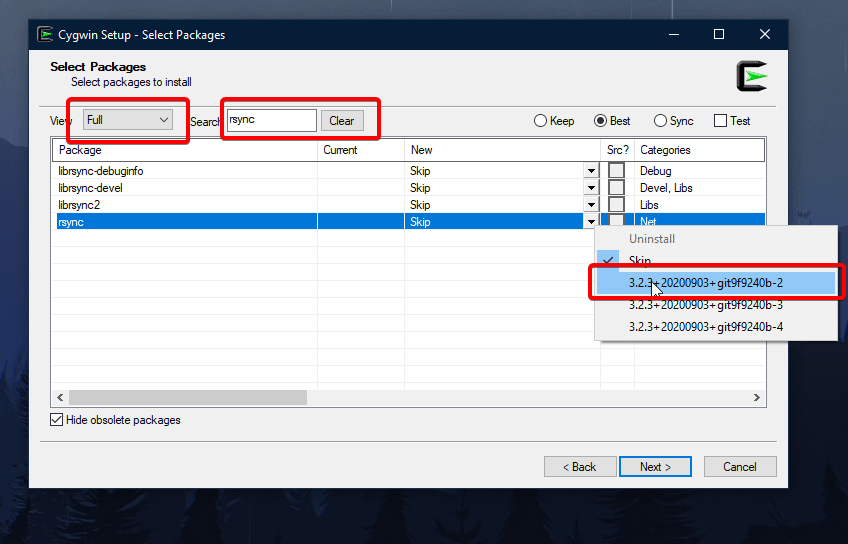
GIF explaining the entire process:

Once the installation is finished, you should see "Cygwin64 Terminal" on your Start Menu. Launch it and you should be greated by the following window:
You may now follow the intructions
Downloading the dataset
Remember that instructions here apply universally, both on Linux and Windows (If you are using Cygwin that is).
The entire dataset weights about 5TB. You are not going to download everything, instead, you are only going to download two kinds of files:
- The images
- The JSON files (metadata)
If you want to see the entire file list, you can refer to the Danbooru2021 information site.
We are going to extract the images from the 512px folder for convinience, since this folder already has the images resized to 512x512 resolution in JPG format. It only has safe rated images, for NSFW refer to gwern.net.
Folders from 0000 to 0009.
The folders are named according to the last 3 digits of the image ID on danbooru. Images on folder 0001 will have its ID end on 001.
We are also going to download the only the first JSON batch. If you want to train on more data you should download more JSON batches.
Download the 512px folders from 0000 to 0009 (3.86GB):
rsync -r rsync://176.9.41.242:873/danbooru2021/512px/000* ./512px/
Download the first batch of metadata, posts000000000000.json (800MB):
rsync rsync://176.9.41.242:873/danbooru2021/metadata/posts000000000000.json ./metadata/
You should now have two folders named: 512px and metadata.
Organizing the dataset
Although we have the dataset, the metadata that explains what the image is, is inside the JSON file. In order to extract the data into individual txt files, we are going to use the script inside danbooru_data/local/extractfromjson_danboo21.py
Assuming you are in the same directory as metadata and 512px folder:
python danbooru_data/local/extractfromjson_danboo21.py -J metadata/posts000000000000.json -E danbooru-aesthetic
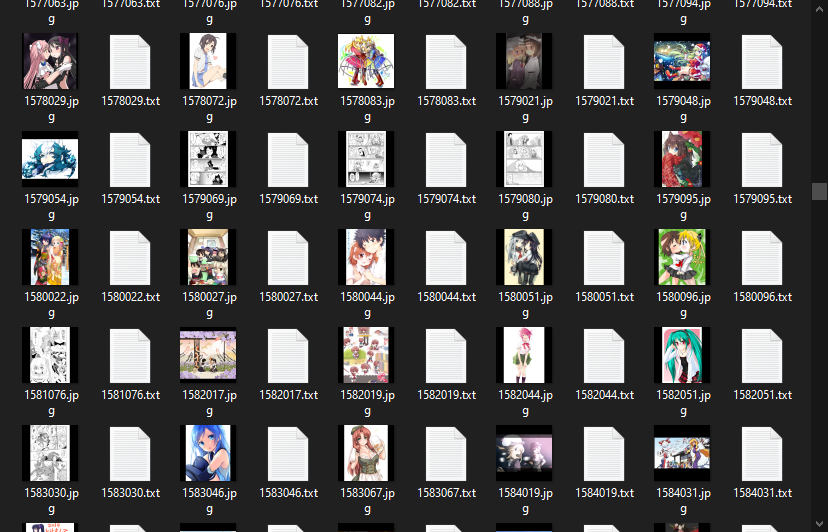
Once the script has finished, you should have a "danbooru-aesthetic" folder, whose insides look like this:
Packaging the dataset
Next we need to put the extracted data into the format required in the section "Dataset requirements". Run the following commands:
mkdir danbooru-aesthetic/img danbooru-aesthetic/txt
mv danbooru-aesthetic/*.jpg labeled_data/img
mv danbooru-aesthetic/*.txt labeled_data/txt
In order to reduce size, zip the contents of labeled_data:
zip -r danbooru-aesthetic.zip danbooru-aesthetic
This will package the entire danbooru-aesthetic folder into a zip file. This command DOES NOT output any information in the terminal, so be patient.
Finish
You can now continue to Configure