2022-06-15 03:50:41 -06:00
< p align = "center" >
< br >
2022-06-15 04:04:28 -06:00
< img src = "docs/source/imgs/diffusers_library.jpg" width = "400" / >
2022-06-15 03:50:41 -06:00
< br >
< p >
< p align = "center" >
2022-06-15 04:04:28 -06:00
< a href = "https://github.com/huggingface/diffusers/blob/main/LICENSE" >
2022-06-15 03:50:41 -06:00
< img alt = "GitHub" src = "https://img.shields.io/github/license/huggingface/datasets.svg?color=blue" >
< / a >
< a href = "https://github.com/huggingface/diffusers/releases" >
2022-06-15 04:04:28 -06:00
< img alt = "GitHub release" src = "https://img.shields.io/github/release/huggingface/diffusers.svg" >
2022-06-15 03:50:41 -06:00
< / a >
< a href = "CODE_OF_CONDUCT.md" >
< img alt = "Contributor Covenant" src = "https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg" >
< / a >
< / p >
🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves
as a modular toolbox for inference and training of diffusion models.
More precisely, 🤗 Diffusers offers:
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines )).
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference (see [src/diffusers/schedulers ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers )).
2022-06-15 03:58:36 -06:00
- Multiple types of models, such as UNet, that can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models )).
2022-06-15 03:54:38 -06:00
- Training examples to show how to train the most popular diffusion models (see [examples ](https://github.com/huggingface/diffusers/tree/main/examples )).
2022-06-01 16:42:08 -06:00
2022-06-02 04:27:01 -06:00
## Definitions
2022-06-02 04:15:59 -06:00
2022-06-15 03:50:41 -06:00
**Models**: Neural network that models **p_θ(x_t-1|x_t)** (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
*Examples*: UNet, Conditioned UNet, 3D UNet, Transformer UNet
2022-06-02 04:27:01 -06:00
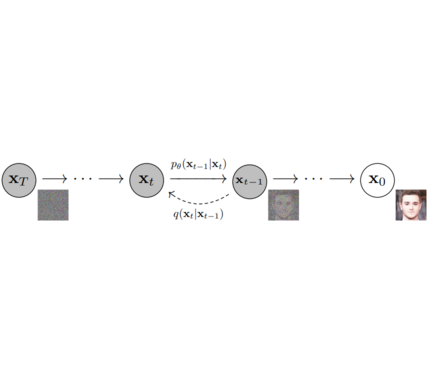
2022-06-15 03:50:41 -06:00
**Schedulers**: Algorithm class for both **inference** and **training** .
The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training.
*Examples*: [DDPM ](https://arxiv.org/abs/2006.11239 ), [DDIM ](https://arxiv.org/abs/2010.02502 ), [PNDM ](https://arxiv.org/abs/2202.09778 ), [DEIS ](https://arxiv.org/abs/2204.13902 )
2022-06-02 04:27:01 -06:00


2022-06-15 03:50:41 -06:00
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ...
*Examples*: GLIDE, Latent-Diffusion, Imagen, DALL-E 2
2022-06-02 04:27:01 -06:00
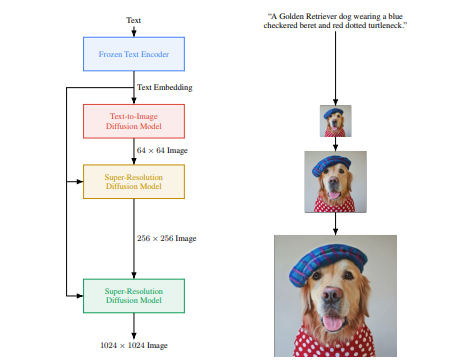
2022-06-02 04:15:59 -06:00
2022-06-15 03:50:41 -06:00
## Philosophy
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code desgin. *E.g.* , the provided [schedulers ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers ) are separated from the provided [models ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models ) and provide well-commented code that can be read alongside the original paper.
- Diffusers is **modality independent** and focusses on providing pretrained models and tools to build systems that generate **continous outputs** , *e.g.* vision and audio.
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are [Glide ](https://github.com/openai/glide-text2im ) and [Latent Diffusion ](https://github.com/CompVis/latent-diffusion ).
2022-06-10 06:36:10 -06:00
## Quickstart
2022-06-15 04:41:57 -06:00
### Installation
2022-06-10 06:37:58 -06:00
```
2022-06-15 08:28:58 -06:00
pip install diffusers # should install diffusers 0.0.4
2022-06-10 06:38:53 -06:00
```
2022-06-10 06:37:58 -06:00
2022-06-15 04:25:48 -06:00
### 1. `diffusers` as a toolbox for schedulers and models.
2022-06-02 07:59:58 -06:00
2022-06-07 09:04:32 -06:00
`diffusers` is more modularized than `transformers` . The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
2022-06-10 06:32:42 -06:00
Both models and schedulers should be load- and saveable from the Hub.
2022-06-02 07:59:58 -06:00
2022-06-15 04:25:48 -06:00
For more examples see [schedulers ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers ) and [models ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models )
2022-06-11 16:24:20 -06:00
#### **Example for [DDPM](https://arxiv.org/abs/2006.11239):**
2022-06-02 07:59:58 -06:00
```python
import torch
2022-06-13 02:39:53 -06:00
from diffusers import UNetModel, DDPMScheduler
2022-06-06 09:43:36 -06:00
import PIL
import numpy as np
2022-06-10 06:37:58 -06:00
import tqdm
2022-06-06 09:43:36 -06:00
2022-06-10 06:32:42 -06:00
generator = torch.manual_seed(0)
2022-06-07 07:13:39 -06:00
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
2022-06-06 09:43:36 -06:00
# 1. Load models
2022-06-13 02:39:53 -06:00
noise_scheduler = DDPMScheduler.from_config("fusing/ddpm-lsun-church", tensor_format="pt")
2022-06-10 06:50:57 -06:00
unet = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
2022-06-06 09:43:36 -06:00
# 2. Sample gaussian noise
2022-06-12 16:14:03 -06:00
image = torch.randn(
2022-06-15 04:41:57 -06:00
(1, unet.in_channels, unet.resolution, unet.resolution),
generator=generator,
2022-06-12 16:14:03 -06:00
)
image = image.to(torch_device)
2022-06-06 09:43:36 -06:00
2022-06-12 16:14:03 -06:00
# 3. Denoise
2022-06-10 06:32:42 -06:00
num_prediction_steps = len(noise_scheduler)
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
2022-06-15 04:41:57 -06:00
# predict noise residual
with torch.no_grad():
2022-06-15 05:27:05 -06:00
residual = unet(image, t)
2022-06-06 09:43:36 -06:00
2022-06-15 04:41:57 -06:00
# predict previous mean of image x_t-1
pred_prev_image = noise_scheduler.step(residual, image, t)
2022-06-10 06:32:42 -06:00
2022-06-15 04:41:57 -06:00
# optionally sample variance
variance = 0
if t > 0:
noise = torch.randn(image.shape, generator=generator).to(image.device)
2022-06-15 05:27:05 -06:00
variance = noise_scheduler.get_variance(t).sqrt() * noise
2022-06-10 06:32:42 -06:00
2022-06-15 04:41:57 -06:00
# set current image to prev_image: x_t -> x_t-1
image = pred_prev_image + variance
2022-06-10 06:32:42 -06:00
# 5. process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# 6. save image
image_pil.save("test.png")
```
2022-06-11 16:24:20 -06:00
#### **Example for [DDIM](https://arxiv.org/abs/2010.02502):**
2022-06-10 06:32:42 -06:00
```python
import torch
from diffusers import UNetModel, DDIMScheduler
import PIL
import numpy as np
2022-06-10 06:37:58 -06:00
import tqdm
2022-06-10 06:32:42 -06:00
generator = torch.manual_seed(0)
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
# 1. Load models
2022-06-12 16:17:26 -06:00
noise_scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
2022-06-10 06:50:57 -06:00
unet = UNetModel.from_pretrained("fusing/ddpm-celeba-hq").to(torch_device)
2022-06-10 06:32:42 -06:00
# 2. Sample gaussian noise
2022-06-12 16:14:03 -06:00
image = torch.randn(
2022-06-12 16:15:39 -06:00
(1, unet.in_channels, unet.resolution, unet.resolution),
generator=generator,
2022-06-12 16:14:03 -06:00
)
image = image.to(torch_device)
2022-06-10 06:32:42 -06:00
# 3. Denoise
num_inference_steps = 50
eta = 0.0 # < - deterministic sampling
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
2022-06-10 06:50:57 -06:00
# 1. predict noise residual
orig_t = noise_scheduler.get_orig_t(t, num_inference_steps)
with torch.no_grad():
residual = unet(image, orig_t)
# 2. predict previous mean of image x_t-1
2022-06-12 11:07:56 -06:00
pred_prev_image = noise_scheduler.step(residual, image, t, num_inference_steps, eta)
2022-06-10 06:50:57 -06:00
# 3. optionally sample variance
variance = 0
if eta > 0:
2022-06-12 16:14:03 -06:00
noise = torch.randn(image.shape, generator=generator).to(image.device)
2022-06-10 06:50:57 -06:00
variance = noise_scheduler.get_variance(t).sqrt() * eta * noise
# 4. set current image to prev_image: x_t -> x_t-1
image = pred_prev_image + variance
2022-06-10 06:32:42 -06:00
# 5. process image to PIL
2022-06-06 09:43:36 -06:00
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
2022-06-06 10:19:02 -06:00
2022-06-10 06:32:42 -06:00
# 6. save image
2022-06-06 09:43:36 -06:00
image_pil.save("test.png")
2022-06-02 07:59:58 -06:00
```
2022-06-15 04:25:48 -06:00
### 2. `diffusers` as a collection of popula Diffusion systems (GLIDE, Dalle, ...)
For more examples see [pipelines ](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines ).
2022-06-02 07:59:58 -06:00
2022-06-15 04:25:48 -06:00
#### **Example image generation with PNDM**
2022-06-02 07:59:58 -06:00
```python
2022-06-15 04:25:48 -06:00
from diffusers import PNDM, UNetModel, PNDMScheduler
2022-06-06 10:19:02 -06:00
import PIL.Image
import numpy as np
2022-06-15 04:25:48 -06:00
import torch
model_id = "fusing/ddim-celeba-hq"
model = UNetModel.from_pretrained(model_id)
scheduler = PNDMScheduler()
2022-06-02 07:59:58 -06:00
2022-06-06 10:19:02 -06:00
# load model and scheduler
2022-06-15 07:59:16 -06:00
pndm = PNDM(unet=model, noise_scheduler=scheduler)
2022-06-06 10:19:02 -06:00
# run pipeline in inference (sample random noise and denoise)
2022-06-15 04:25:48 -06:00
with torch.no_grad():
2022-06-15 07:59:16 -06:00
image = pndm()
2022-06-02 07:59:58 -06:00
2022-06-06 10:19:02 -06:00
# process image to PIL
2022-06-06 10:17:15 -06:00
image_processed = image.cpu().permute(0, 2, 3, 1)
2022-06-15 04:25:48 -06:00
image_processed = (image_processed + 1.0) / 2
image_processed = torch.clamp(image_processed, 0.0, 1.0)
image_processed = image_processed * 255
2022-06-06 10:17:15 -06:00
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
2022-06-06 10:19:02 -06:00
# save image
2022-06-06 10:17:15 -06:00
image_pil.save("test.png")
2022-06-02 07:59:58 -06:00
```
2022-06-13 09:16:40 -06:00
#### **Text to Image generation with Latent Diffusion**
2022-06-10 08:33:58 -06:00
2022-06-15 02:42:37 -06:00
_Note: To use latent diffusion install transformers from [this branch ](https://github.com/patil-suraj/transformers/tree/ldm-bert )._
2022-06-10 08:33:58 -06:00
```python
from diffusers import DiffusionPipeline
ldm = DiffusionPipeline.from_pretrained("fusing/latent-diffusion-text2im-large")
2022-06-15 02:42:37 -06:00
generator = torch.manual_seed(42)
2022-06-10 08:33:58 -06:00
prompt = "A painting of a squirrel eating a burger"
image = ldm([prompt], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50)
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = image_processed * 255.
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
```
2022-06-13 09:16:40 -06:00
#### **Text to speech with BDDM**
2022-06-13 09:13:31 -06:00
2022-06-15 09:01:48 -06:00
_Follow the instructions [here ](https://pytorch.org/hub/nvidia_deeplearningexamples_tacotron2/ ) to load tacotron2 model._
2022-06-13 09:13:31 -06:00
```python
import torch
from diffusers import BDDM, DiffusionPipeline
torch_device = "cuda"
# load the BDDM pipeline
2022-06-15 01:44:18 -06:00
bddm = DiffusionPipeline.from_pretrained("fusing/diffwave-vocoder-ljspeech")
2022-06-13 09:13:31 -06:00
# load tacotron2 to get the mel spectograms
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')
tacotron2 = tacotron2.to(torch_device).eval()
text = "Hello world, I missed you so much."
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
sequences, lengths = utils.prepare_input_sequence([text])
2022-06-13 09:15:52 -06:00
# generate mel spectograms using text
2022-06-13 09:13:31 -06:00
with torch.no_grad():
2022-06-13 09:15:52 -06:00
mel_spec, _, _ = tacotron2.infer(sequences, lengths)
2022-06-13 09:13:31 -06:00
2022-06-13 09:15:52 -06:00
# generate the speech by passing mel spectograms to BDDM pipeline
2022-06-13 09:13:31 -06:00
generator = torch.manual_seed(0)
2022-06-13 09:15:52 -06:00
audio = bddm(mel_spec, generator, torch_device)
2022-06-13 09:13:31 -06:00
2022-06-13 09:15:52 -06:00
# save generated audio
2022-06-13 09:13:31 -06:00
from scipy.io.wavfile import write as wavwrite
sampling_rate = 22050
wavwrite("generated_audio.wav", sampling_rate, audio.squeeze().cpu().numpy())
```
2022-06-15 07:44:38 -06:00
## TODO
- Create common API for models [ ]
- Add tests for models [ ]
- Adapt schedulers for training [ ]
- Write google colab for training [ ]
- Write docs / Think about how to structure docs [ ]
- Add tests to circle ci [ ]
- Add more vision models [ ]
- Add more speech models [ ]
- Add RL model [ ]